forked from cory/tildefriends
Use picohttpparser. No more messing around.
git-svn-id: https://www.unprompted.com/svn/projects/tildefriends/trunk@4094 ed5197a5-7fde-0310-b194-c3ffbd925b24
This commit is contained in:
116
deps/picohttpparser/README.md
vendored
Normal file
116
deps/picohttpparser/README.md
vendored
Normal file
@@ -0,0 +1,116 @@
|
||||
PicoHTTPParser
|
||||
=============
|
||||
|
||||
Copyright (c) 2009-2014 [Kazuho Oku](https://github.com/kazuho), [Tokuhiro Matsuno](https://github.com/tokuhirom), [Daisuke Murase](https://github.com/typester), [Shigeo Mitsunari](https://github.com/herumi)
|
||||
|
||||
PicoHTTPParser is a tiny, primitive, fast HTTP request/response parser.
|
||||
|
||||
Unlike most parsers, it is stateless and does not allocate memory by itself.
|
||||
All it does is accept pointer to buffer and the output structure, and setups the pointers in the latter to point at the necessary portions of the buffer.
|
||||
|
||||
The code is widely deployed within Perl applications through popular modules that use it, including [Plack](https://metacpan.org/pod/Plack), [Starman](https://metacpan.org/pod/Starman), [Starlet](https://metacpan.org/pod/Starlet), [Furl](https://metacpan.org/pod/Furl). It is also the HTTP/1 parser of [H2O](https://github.com/h2o/h2o).
|
||||
|
||||
Check out [test.c] to find out how to use the parser.
|
||||
|
||||
The software is dual-licensed under the Perl License or the MIT License.
|
||||
|
||||
Usage
|
||||
-----
|
||||
|
||||
The library exposes four functions: `phr_parse_request`, `phr_parse_response`, `phr_parse_headers`, `phr_decode_chunked`.
|
||||
|
||||
### phr_parse_request
|
||||
|
||||
The example below reads an HTTP request from socket `sock` using `read(2)`, parses it using `phr_parse_request`, and prints the details.
|
||||
|
||||
```c
|
||||
char buf[4096], *method, *path;
|
||||
int pret, minor_version;
|
||||
struct phr_header headers[100];
|
||||
size_t buflen = 0, prevbuflen = 0, method_len, path_len, num_headers;
|
||||
ssize_t rret;
|
||||
|
||||
while (1) {
|
||||
/* read the request */
|
||||
while ((rret = read(sock, buf + buflen, sizeof(buf) - buflen)) == -1 && errno == EINTR)
|
||||
;
|
||||
if (rret <= 0)
|
||||
return IOError;
|
||||
prevbuflen = buflen;
|
||||
buflen += rret;
|
||||
/* parse the request */
|
||||
num_headers = sizeof(headers) / sizeof(headers[0]);
|
||||
pret = phr_parse_request(buf, buflen, &method, &method_len, &path, &path_len,
|
||||
&minor_version, headers, &num_headers, prevbuflen);
|
||||
if (pret > 0)
|
||||
break; /* successfully parsed the request */
|
||||
else if (pret == -1)
|
||||
return ParseError;
|
||||
/* request is incomplete, continue the loop */
|
||||
assert(pret == -2);
|
||||
if (buflen == sizeof(buf))
|
||||
return RequestIsTooLongError;
|
||||
}
|
||||
|
||||
printf("request is %d bytes long\n", pret);
|
||||
printf("method is %.*s\n", (int)method_len, method);
|
||||
printf("path is %.*s\n", (int)path_len, path);
|
||||
printf("HTTP version is 1.%d\n", minor_version);
|
||||
printf("headers:\n");
|
||||
for (i = 0; i != num_headers; ++i) {
|
||||
printf("%.*s: %.*s\n", (int)headers[i].name_len, headers[i].name,
|
||||
(int)headers[i].value_len, headers[i].value);
|
||||
}
|
||||
```
|
||||
|
||||
### phr_parse_response, phr_parse_headers
|
||||
|
||||
`phr_parse_response` and `phr_parse_headers` provide similar interfaces as `phr_parse_request`. `phr_parse_response` parses an HTTP response, and `phr_parse_headers` parses the headers only.
|
||||
|
||||
### phr_decode_chunked
|
||||
|
||||
The example below decodes incoming data in chunked-encoding. The data is decoded in-place.
|
||||
|
||||
```c
|
||||
struct phr_chunked_decoder decoder = {}; /* zero-clear */
|
||||
char *buf = malloc(4096);
|
||||
size_t size = 0, capacity = 4096, rsize;
|
||||
ssize_t rret, pret;
|
||||
|
||||
/* set consume_trailer to 1 to discard the trailing header, or the application
|
||||
* should call phr_parse_headers to parse the trailing header */
|
||||
decoder.consume_trailer = 1;
|
||||
|
||||
do {
|
||||
/* expand the buffer if necessary */
|
||||
if (size == capacity) {
|
||||
capacity *= 2;
|
||||
buf = realloc(buf, capacity);
|
||||
assert(buf != NULL);
|
||||
}
|
||||
/* read */
|
||||
while ((rret = read(sock, buf + size, capacity - size)) == -1 && errno == EINTR)
|
||||
;
|
||||
if (rret <= 0)
|
||||
return IOError;
|
||||
/* decode */
|
||||
rsize = rret;
|
||||
pret = phr_decode_chunked(&decoder, buf + size, &rsize);
|
||||
if (pret == -1)
|
||||
return ParseError;
|
||||
size += rsize;
|
||||
} while (pret == -2);
|
||||
|
||||
/* successfully decoded the chunked data */
|
||||
assert(pret >= 0);
|
||||
printf("decoded data is at %p (%zu bytes)\n", buf, size);
|
||||
```
|
||||
|
||||
Benchmark
|
||||
---------
|
||||
|
||||
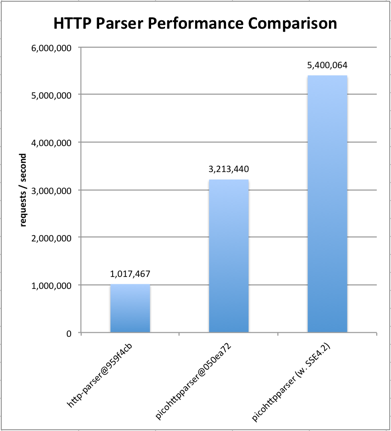
|
||||
|
||||
The benchmark code is from [fukamachi/fast-http@6b91103](https://github.com/fukamachi/fast-http/tree/6b9110347c7a3407310c08979aefd65078518478).
|
||||
|
||||
The internals of picohttpparser has been described to some extent in [my blog entry]( http://blog.kazuhooku.com/2014/11/the-internals-h2o-or-how-to-write-fast.html).
|
||||
Reference in New Issue
Block a user