Use picohttpparser. No more messing around.
git-svn-id: https://www.unprompted.com/svn/projects/tildefriends/trunk@4094 ed5197a5-7fde-0310-b194-c3ffbd925b24
This commit is contained in:
7
Makefile
7
Makefile
@@ -69,6 +69,7 @@ $(APP_OBJS): CFLAGS += \
|
||||
-Ideps/libsodium \
|
||||
-Ideps/libsodium/src/libsodium/include \
|
||||
-Ideps/libuv/include \
|
||||
-Ideps/picohttpparser \
|
||||
-Ideps/quickjs \
|
||||
-Ideps/sqlite \
|
||||
-Ideps/valgrind \
|
||||
@@ -295,6 +296,11 @@ $(LIBBACKTRACE_OBJS): CFLAGS += \
|
||||
-Wno-unused-function \
|
||||
-DBACKTRACE_ELF_SIZE=64
|
||||
|
||||
PICOHTTPPARSER_SOURCES := \
|
||||
deps/picohttpparser/picohttpparser.c
|
||||
PICOHTTPPARSER_OBJS := $(call get_objs,PICOHTTPPARSER_SOURCES)
|
||||
# $(PICOHTTPPARSER_OBJS): CFLAGS +=
|
||||
|
||||
LDFLAGS += \
|
||||
-pthread \
|
||||
-lm
|
||||
@@ -327,6 +333,7 @@ ALL_APP_OBJS := \
|
||||
$(BASE64C_OBJS) \
|
||||
$(BLOWFISH_OBJS) \
|
||||
$(LIBBACKTRACE_OBJS) \
|
||||
$(PICOHTTPPARSER_OBJS) \
|
||||
$(QUICKJS_OBJS) \
|
||||
$(SODIUM_OBJS) \
|
||||
$(SQLITE_OBJS) \
|
||||
|
||||
319
core/httpd.js
319
core/httpd.js
@@ -2,9 +2,9 @@ import * as sha1 from './sha1.js';
|
||||
|
||||
"use strict";
|
||||
|
||||
var gHandlers = [];
|
||||
var gSocketHandlers = [];
|
||||
var gBadRequests = {};
|
||||
let gHandlers = [];
|
||||
let gSocketHandlers = [];
|
||||
let gBadRequests = {};
|
||||
|
||||
const kRequestTimeout = 15000;
|
||||
const kStallTimeout = 60000;
|
||||
@@ -17,8 +17,8 @@ function logError(error) {
|
||||
}
|
||||
|
||||
function addHandler(handler) {
|
||||
var added = false;
|
||||
for (var i in gHandlers) {
|
||||
let added = false;
|
||||
for (let i in gHandlers) {
|
||||
if (gHandlers[i].path == handler.path) {
|
||||
gHandlers[i] = handler;
|
||||
added = true;
|
||||
@@ -49,7 +49,7 @@ function registerSocketHandler(prefix, handler) {
|
||||
|
||||
function Request(method, uri, version, headers, body, client) {
|
||||
this.method = method;
|
||||
var index = uri.indexOf("?");
|
||||
let index = uri.indexOf("?");
|
||||
if (index != -1) {
|
||||
this.uri = uri.slice(0, index);
|
||||
this.query = uri.slice(index + 1);
|
||||
@@ -65,9 +65,9 @@ function Request(method, uri, version, headers, body, client) {
|
||||
}
|
||||
|
||||
function findHandler(request) {
|
||||
var matchedHandler = null;
|
||||
for (var name in gHandlers) {
|
||||
var handler = gHandlers[name];
|
||||
let matchedHandler = null;
|
||||
for (let name in gHandlers) {
|
||||
let handler = gHandlers[name];
|
||||
if (request.uri == handler.path || request.uri.slice(0, handler.path.length + 1) == handler.path + '/') {
|
||||
matchedHandler = handler;
|
||||
break;
|
||||
@@ -77,9 +77,9 @@ function findHandler(request) {
|
||||
}
|
||||
|
||||
function findSocketHandler(request) {
|
||||
var matchedHandler = null;
|
||||
for (var name in gSocketHandlers) {
|
||||
var handler = gSocketHandlers[name];
|
||||
let matchedHandler = null;
|
||||
for (let name in gSocketHandlers) {
|
||||
let handler = gSocketHandlers[name];
|
||||
if (request.uri == handler.path || request.uri.slice(0, handler.path.length + 1) == handler.path + '/') {
|
||||
matchedHandler = handler;
|
||||
break;
|
||||
@@ -89,7 +89,7 @@ function findSocketHandler(request) {
|
||||
}
|
||||
|
||||
function Response(request, client) {
|
||||
var kStatusText = {
|
||||
let kStatusText = {
|
||||
101: "Switching Protocols",
|
||||
200: 'OK',
|
||||
303: 'See other',
|
||||
@@ -99,17 +99,17 @@ function Response(request, client) {
|
||||
404: 'File not found',
|
||||
500: 'Internal server error',
|
||||
};
|
||||
var _started = false;
|
||||
var _finished = false;
|
||||
var _keepAlive = false;
|
||||
var _chunked = false;
|
||||
let _started = false;
|
||||
let _finished = false;
|
||||
let _keepAlive = false;
|
||||
let _chunked = false;
|
||||
return {
|
||||
writeHead: function(status) {
|
||||
if (_started) {
|
||||
throw new Error("Response.writeHead called multiple times.");
|
||||
}
|
||||
var reason;
|
||||
var headers;
|
||||
let reason;
|
||||
let headers;
|
||||
if (arguments.length == 3) {
|
||||
reason = arguments[1];
|
||||
headers = arguments[2];
|
||||
@@ -117,11 +117,11 @@ function Response(request, client) {
|
||||
reason = kStatusText[status];
|
||||
headers = arguments[1];
|
||||
}
|
||||
var lowerHeaders = {};
|
||||
var requestVersion = request.version.split("/")[1].split(".");
|
||||
var responseVersion = (requestVersion[0] >= 1 && requestVersion[0] >= 1) ? "1.1" : "1.0";
|
||||
var headerString = "HTTP/" + responseVersion + " " + status + " " + reason + "\r\n";
|
||||
for (var i in headers) {
|
||||
let lowerHeaders = {};
|
||||
let requestVersion = request.version.split("/")[1].split(".");
|
||||
let responseVersion = (requestVersion[0] >= 1 && requestVersion[0] >= 1) ? "1.1" : "1.0";
|
||||
let headerString = "HTTP/" + responseVersion + " " + status + " " + reason + "\r\n";
|
||||
for (let i in headers) {
|
||||
headerString += i + ": " + headers[i] + "\r\n";
|
||||
lowerHeaders[i.toLowerCase()] = headers[i];
|
||||
}
|
||||
@@ -172,13 +172,13 @@ function Response(request, client) {
|
||||
}
|
||||
|
||||
function handleRequest(request, response) {
|
||||
var handler = findHandler(request);
|
||||
let handler = findHandler(request);
|
||||
|
||||
print(request.client.peerName + " - - [" + new Date() + "] " + request.method + " " + request.uri + " " + request.version + " \"" + request.headers["user-agent"] + "\"");
|
||||
|
||||
if (handler) {
|
||||
try {
|
||||
var promise = handler.invoke(request, response);
|
||||
let promise = handler.invoke(request, response);
|
||||
if (promise) {
|
||||
promise.catch(function(error) {
|
||||
response.reportError(error);
|
||||
@@ -196,11 +196,11 @@ function handleRequest(request, response) {
|
||||
}
|
||||
|
||||
function handleWebSocketRequest(request, response, client) {
|
||||
var buffer = new Uint8Array(0);
|
||||
var frame = new Uint8Array(0);
|
||||
var frameOpCode = 0x0;
|
||||
let buffer = new Uint8Array(0);
|
||||
let frame = new Uint8Array(0);
|
||||
let frameOpCode = 0x0;
|
||||
|
||||
var handler = findSocketHandler(request);
|
||||
let handler = findSocketHandler(request);
|
||||
if (!handler) {
|
||||
client.close();
|
||||
return;
|
||||
@@ -213,9 +213,9 @@ function handleWebSocketRequest(request, response, client) {
|
||||
if (opCode == 0x1 && (typeof message == "string" || message instanceof String)) {
|
||||
message = utf8Encode(message);
|
||||
}
|
||||
var fin = true;
|
||||
var packet = [(fin ? (1 << 7) : 0) | (opCode & 0xf)];
|
||||
var mask = false;
|
||||
let fin = true;
|
||||
let packet = [(fin ? (1 << 7) : 0) | (opCode & 0xf)];
|
||||
let mask = false;
|
||||
if (message.length < 126) {
|
||||
packet.push((mask ? (1 << 7) : 0) | message.length);
|
||||
} else if (message.length < (1 << 16)) {
|
||||
@@ -223,8 +223,8 @@ function handleWebSocketRequest(request, response, client) {
|
||||
packet.push((message.length >> 8) & 0xff);
|
||||
packet.push(message.length & 0xff);
|
||||
} else {
|
||||
var high = 0; //(message.length / (1 ** 32)) & 0xffffffff;
|
||||
var low = message.length & 0xffffffff;
|
||||
let high = 0; //(message.length / (1 ** 32)) & 0xffffffff;
|
||||
let low = message.length & 0xffffffff;
|
||||
packet.push((mask ? (1 << 7) : 0) | 127);
|
||||
packet.push((high >> 24) & 0xff);
|
||||
packet.push((high >> 16) & 0xff);
|
||||
@@ -236,7 +236,7 @@ function handleWebSocketRequest(request, response, client) {
|
||||
packet.push(low & 0xff);
|
||||
}
|
||||
|
||||
var array = new Uint8Array(packet.length + message.length);
|
||||
let array = new Uint8Array(packet.length + message.length);
|
||||
array.set(packet, 0);
|
||||
array.set(message, packet.length);
|
||||
try {
|
||||
@@ -252,50 +252,50 @@ function handleWebSocketRequest(request, response, client) {
|
||||
|
||||
client.read(function(data) {
|
||||
if (data) {
|
||||
var newBuffer = new Uint8Array(buffer.length + data.length);
|
||||
let newBuffer = new Uint8Array(buffer.length + data.length);
|
||||
newBuffer.set(buffer, 0);
|
||||
newBuffer.set(data, buffer.length);
|
||||
buffer = newBuffer;
|
||||
|
||||
while (buffer.length >= 2) {
|
||||
var bits0 = buffer[0];
|
||||
var bits1 = buffer[1];
|
||||
let bits0 = buffer[0];
|
||||
let bits1 = buffer[1];
|
||||
if (bits1 & (1 << 7) == 0) {
|
||||
// Unmasked message.
|
||||
client.close();
|
||||
}
|
||||
var opCode = bits0 & 0xf;
|
||||
var fin = bits0 & (1 << 7);
|
||||
var payloadLength = bits1 & 0x7f;
|
||||
var maskStart = 2;
|
||||
let opCode = bits0 & 0xf;
|
||||
let fin = bits0 & (1 << 7);
|
||||
let payloadLength = bits1 & 0x7f;
|
||||
let maskStart = 2;
|
||||
|
||||
if (payloadLength == 126) {
|
||||
payloadLength = 0;
|
||||
for (var i = 0; i < 2; i++) {
|
||||
for (let i = 0; i < 2; i++) {
|
||||
payloadLength <<= 8;
|
||||
payloadLength |= buffer[2 + i];
|
||||
}
|
||||
maskStart = 4;
|
||||
} else if (payloadLength == 127) {
|
||||
payloadLength = 0;
|
||||
for (var i = 0; i < 8; i++) {
|
||||
for (let i = 0; i < 8; i++) {
|
||||
payloadLength <<= 8;
|
||||
payloadLength |= buffer[2 + i];
|
||||
}
|
||||
maskStart = 10;
|
||||
}
|
||||
var havePayload = buffer.length >= payloadLength + 2 + 4;
|
||||
let havePayload = buffer.length >= payloadLength + 2 + 4;
|
||||
if (havePayload) {
|
||||
var mask = buffer.slice(maskStart, maskStart + 4);
|
||||
var dataStart = maskStart + 4;
|
||||
var decoded = new Array(payloadLength);
|
||||
var payload = buffer.slice(dataStart, dataStart + payloadLength);
|
||||
let mask = buffer.slice(maskStart, maskStart + 4);
|
||||
let dataStart = maskStart + 4;
|
||||
let decoded = new Array(payloadLength);
|
||||
let payload = buffer.slice(dataStart, dataStart + payloadLength);
|
||||
buffer = buffer.slice(dataStart + payloadLength);
|
||||
for (var i = 0; i < payloadLength; i++) {
|
||||
for (let i = 0; i < payloadLength; i++) {
|
||||
decoded[i] = payload[i] ^ mask[i % 4];
|
||||
}
|
||||
|
||||
var newBuffer = new Uint8Array(frame.length + decoded.length);
|
||||
let newBuffer = new Uint8Array(frame.length + decoded.length);
|
||||
newBuffer.set(frame, 0);
|
||||
newBuffer.set(decoded, frame.length);
|
||||
frame = newBuffer;
|
||||
@@ -339,17 +339,17 @@ function handleWebSocketRequest(request, response, client) {
|
||||
}
|
||||
|
||||
function webSocketAcceptResponse(key) {
|
||||
var kMagic = "258EAFA5-E914-47DA-95CA-C5AB0DC85B11";
|
||||
var kAlphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
|
||||
var hex = sha1.hash(key + kMagic)
|
||||
var binary = "";
|
||||
for (var i = 0; i < hex.length; i += 6) {
|
||||
var characters = hex.substring(i, i + 6);
|
||||
let kMagic = "258EAFA5-E914-47DA-95CA-C5AB0DC85B11";
|
||||
let kAlphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=";
|
||||
let hex = sha1.hash(key + kMagic)
|
||||
let binary = "";
|
||||
for (let i = 0; i < hex.length; i += 6) {
|
||||
let characters = hex.substring(i, i + 6);
|
||||
if (characters.length < 6) {
|
||||
characters += "0".repeat(6 - characters.length);
|
||||
}
|
||||
var value = parseInt(characters, 16);
|
||||
for (var bit = 0; bit < 8 * 3; bit += 6) {
|
||||
let value = parseInt(characters, 16);
|
||||
for (let bit = 0; bit < 8 * 3; bit += 6) {
|
||||
if (i * 8 / 2 + bit >= 8 * hex.length / 2) {
|
||||
binary += kAlphabet.charAt(64);
|
||||
} else {
|
||||
@@ -361,9 +361,9 @@ function webSocketAcceptResponse(key) {
|
||||
}
|
||||
|
||||
function badRequest(client, reason) {
|
||||
var now = new Date();
|
||||
var count = 0;
|
||||
var old = gBadRequests[client.peerName];
|
||||
let now = new Date();
|
||||
let count = 0;
|
||||
let old = gBadRequests[client.peerName];
|
||||
if (!old) {
|
||||
gBadRequests[client.peerName] = {
|
||||
expire: new Date(now.getTime() + 1 * 60 * 1000),
|
||||
@@ -381,9 +381,9 @@ function badRequest(client, reason) {
|
||||
}
|
||||
|
||||
function allowRequest(client) {
|
||||
var old = gBadRequests[client.peerName];
|
||||
let old = gBadRequests[client.peerName];
|
||||
if (old) {
|
||||
var now = new Date();
|
||||
let now = new Date();
|
||||
if (old.expire < now) {
|
||||
delete gBadRequests[client.peerName];
|
||||
return true;
|
||||
@@ -404,15 +404,15 @@ function handleConnection(client) {
|
||||
}
|
||||
|
||||
client.info = 'accepted';
|
||||
var inputBuffer = new Uint8Array(0);
|
||||
var request;
|
||||
var headers = {};
|
||||
var lineByLine = true;
|
||||
var bodyToRead = -1;
|
||||
var body;
|
||||
var requestCount = -1;
|
||||
var readCount = 0;
|
||||
var isWebsocket = false;
|
||||
let inputBuffer = new Uint8Array(0);
|
||||
let request;
|
||||
let headers = {};
|
||||
let parsing_header = true;
|
||||
let bodyToRead = -1;
|
||||
let body;
|
||||
let requestCount = -1;
|
||||
let readCount = 0;
|
||||
let isWebsocket = false;
|
||||
|
||||
function resetTimeout(requestIndex) {
|
||||
if (isWebsocket) {
|
||||
@@ -430,7 +430,7 @@ function handleConnection(client) {
|
||||
}
|
||||
}, kRequestTimeout);
|
||||
} else {
|
||||
var lastReadCount = readCount;
|
||||
let lastReadCount = readCount;
|
||||
setTimeout(function() {
|
||||
if (readCount == lastReadCount) {
|
||||
client.info = 'stalled';
|
||||
@@ -450,7 +450,7 @@ function handleConnection(client) {
|
||||
inputBuffer = new Uint8Array(0);
|
||||
request = undefined;
|
||||
headers = {};
|
||||
lineByLine = true;
|
||||
parsing_header = true;
|
||||
bodyToRead = -1;
|
||||
body = undefined;
|
||||
client.info = 'reset';
|
||||
@@ -459,8 +459,8 @@ function handleConnection(client) {
|
||||
|
||||
function finish() {
|
||||
client.info = 'finishing';
|
||||
var requestObject = new Request(request[0], request[1], request[2], headers, body, client);
|
||||
var response = new Response(requestObject, client);
|
||||
let requestObject = new Request(request[0], request[1], request[2], headers, body, client);
|
||||
let response = new Response(requestObject, client);
|
||||
try {
|
||||
handleRequest(requestObject, response)
|
||||
if (client.isConnected) {
|
||||
@@ -472,69 +472,6 @@ function handleConnection(client) {
|
||||
}
|
||||
}
|
||||
|
||||
function handleLine(line, length) {
|
||||
if (bodyToRead == -1) {
|
||||
line = utf8Decode(line);
|
||||
if (!request) {
|
||||
if (!line) {
|
||||
badRequest(client, 'Empty request.');
|
||||
return false;
|
||||
}
|
||||
request = line.split(' ');
|
||||
if (request.length != 3 || !request[2].startsWith('HTTP/1.')) {
|
||||
badRequest(client, 'Bad request.');
|
||||
request = null;
|
||||
return false;
|
||||
}
|
||||
return true;
|
||||
} else if (line) {
|
||||
var colon = line.indexOf(':');
|
||||
var key = line.slice(0, colon).trim();
|
||||
var value = line.slice(colon + 1).trim();
|
||||
headers[key.toLowerCase()] = value;
|
||||
return true;
|
||||
} else {
|
||||
if (headers["content-length"] != undefined) {
|
||||
bodyToRead = parseInt(headers["content-length"]);
|
||||
lineByLine = false;
|
||||
if (bodyToRead > 16 * 1024 * 1024) {
|
||||
badRequest(client, 'Request too large: ' + bodyToRead + '.');
|
||||
return false;
|
||||
}
|
||||
body = new Uint8Array(bodyToRead);
|
||||
client.info = 'waiting for body';
|
||||
resetTimeout(requestCount);
|
||||
return true;
|
||||
} else if (headers["connection"]
|
||||
&& headers["connection"].toLowerCase().split(",").map(x => x.trim()).indexOf("upgrade") != -1
|
||||
&& headers["upgrade"]
|
||||
&& headers["upgrade"].toLowerCase() == "websocket") {
|
||||
isWebsocket = true;
|
||||
client.info = 'websocket';
|
||||
var requestObject = new Request(request[0], request[1], request[2], headers, body, client);
|
||||
var response = new Response(requestObject, client);
|
||||
handleWebSocketRequest(requestObject, response, client);
|
||||
/* Prevent the timeout from disconnecting us. */
|
||||
requestCount++;
|
||||
return false;
|
||||
} else {
|
||||
finish();
|
||||
return false;
|
||||
}
|
||||
}
|
||||
} else {
|
||||
var offset = body.length - bodyToRead;
|
||||
if (line.length > body.length - offset) {
|
||||
line = line.slice(0, body.length - offset);
|
||||
}
|
||||
body.set(line, offset);
|
||||
bodyToRead -= line.length;
|
||||
if (bodyToRead <= 0) {
|
||||
finish();
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
client.noDelay = true;
|
||||
|
||||
client.onError(function(error) {
|
||||
@@ -547,36 +484,72 @@ function handleConnection(client) {
|
||||
if (bodyToRead != -1 && !isWebsocket) {
|
||||
resetTimeout(requestCount);
|
||||
}
|
||||
const kMaxLineLength = 4096;
|
||||
var newBuffer = new Uint8Array(inputBuffer.length + data.length);
|
||||
let newBuffer = new Uint8Array(inputBuffer.length + data.length);
|
||||
newBuffer.set(inputBuffer, 0);
|
||||
newBuffer.set(data, inputBuffer.length);
|
||||
inputBuffer = newBuffer;
|
||||
|
||||
var newLine = '\n'.charCodeAt(0);
|
||||
var carriageReturn = '\r'.charCodeAt(0);
|
||||
|
||||
var more = true;
|
||||
while (more) {
|
||||
if (lineByLine) {
|
||||
more = false;
|
||||
var end = inputBuffer.indexOf(newLine);
|
||||
var realEnd = end;
|
||||
if (end > 0 && inputBuffer[end - 1] == carriageReturn) {
|
||||
--end;
|
||||
}
|
||||
if (end > kMaxLineLength || end == -1 && inputBuffer.length > kMaxLineLength) {
|
||||
badRequest(client, 'Request too long.');
|
||||
if (parsing_header)
|
||||
{
|
||||
let result = parseHttp(inputBuffer, inputBuffer.length - data.length);
|
||||
if (result) {
|
||||
if (typeof result === 'number') {
|
||||
if (result == -2) {
|
||||
/* More. */
|
||||
} else {
|
||||
badRequest(client, 'Bad request.');
|
||||
return;
|
||||
}
|
||||
if (end != -1) {
|
||||
var line = inputBuffer.slice(0, end);
|
||||
inputBuffer = inputBuffer.slice(realEnd + 1);
|
||||
more = handleLine(line, realEnd + 1);
|
||||
} else if (typeof result === 'object') {
|
||||
request = [
|
||||
result.method,
|
||||
result.path,
|
||||
`HTTP/1.${result.minor_version}`,
|
||||
];
|
||||
headers = Object.fromEntries(Object.entries(result.headers).map(x => [x[0].toLowerCase(), x[1]]));
|
||||
parsing_header = false;
|
||||
inputBuffer = inputBuffer.slice(result.bytes_parsed);
|
||||
|
||||
if (headers["content-length"] != undefined) {
|
||||
bodyToRead = parseInt(headers["content-length"]);
|
||||
if (bodyToRead > 16 * 1024 * 1024) {
|
||||
badRequest(client, 'Request too large: ' + bodyToRead + '.');
|
||||
return;
|
||||
}
|
||||
body = new Uint8Array(bodyToRead);
|
||||
client.info = 'waiting for body';
|
||||
resetTimeout(requestCount);
|
||||
} else if (headers["connection"]
|
||||
&& headers["connection"].toLowerCase().split(",").map(x => x.trim()).indexOf("upgrade") != -1
|
||||
&& headers["upgrade"]
|
||||
&& headers["upgrade"].toLowerCase() == "websocket") {
|
||||
isWebsocket = true;
|
||||
client.info = 'websocket';
|
||||
let requestObject = new Request(request[0], request[1], request[2], headers, body, client);
|
||||
let response = new Response(requestObject, client);
|
||||
handleWebSocketRequest(requestObject, response, client);
|
||||
/* Prevent the timeout from disconnecting us. */
|
||||
requestCount++;
|
||||
} else {
|
||||
more = handleLine(inputBuffer, inputBuffer.length);
|
||||
inputBuffer = new Uint8Array(0);
|
||||
finish();
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
|
||||
if (!parsing_header && inputBuffer.length)
|
||||
{
|
||||
let offset = body.length - bodyToRead;
|
||||
let length = Math.min(inputBuffer.length, body.length - offset);
|
||||
if (inputBuffer.length > body.length - offset) {
|
||||
body.set(inputBuffer.slice(0, length), offset);
|
||||
inputBuffer = inputBuffer.slice(length);
|
||||
} else {
|
||||
body.set(inputBuffer, offset);
|
||||
}
|
||||
bodyToRead -= length;
|
||||
if (bodyToRead <= 0) {
|
||||
finish();
|
||||
}
|
||||
}
|
||||
} else {
|
||||
@@ -586,12 +559,12 @@ function handleConnection(client) {
|
||||
});
|
||||
}
|
||||
|
||||
var kBacklog = 8;
|
||||
var kHost = "0.0.0.0"
|
||||
let kBacklog = 8;
|
||||
let kHost = "0.0.0.0"
|
||||
|
||||
var socket = new Socket();
|
||||
let socket = new Socket();
|
||||
socket.bind(kHost, tildefriends.http_port).then(function() {
|
||||
var listenResult = socket.listen(kBacklog, function() {
|
||||
let listenResult = socket.listen(kBacklog, function() {
|
||||
socket.accept().then(handleConnection).catch(function(error) {
|
||||
logError("[" + new Date() + "] accept error " + error);
|
||||
});
|
||||
@@ -601,17 +574,17 @@ socket.bind(kHost, tildefriends.http_port).then(function() {
|
||||
});
|
||||
|
||||
if (tildefriends.https_port) {
|
||||
var tls = {};
|
||||
var secureSocket = new Socket();
|
||||
let tls = {};
|
||||
let secureSocket = new Socket();
|
||||
secureSocket.bind(kHost, tildefriends.https_port).then(function() {
|
||||
return secureSocket.listen(kBacklog, async function() {
|
||||
try {
|
||||
var client = await secureSocket.accept();
|
||||
let client = await secureSocket.accept();
|
||||
client.tls = true;
|
||||
const kCertificatePath = "data/httpd/certificate.pem";
|
||||
const kPrivateKeyPath = "data/httpd/privatekey.pem";
|
||||
|
||||
var stat = await Promise.all([
|
||||
let stat = await Promise.all([
|
||||
await File.stat(kCertificatePath),
|
||||
await File.stat(kPrivateKeyPath),
|
||||
]);
|
||||
@@ -621,8 +594,8 @@ if (tildefriends.https_port) {
|
||||
tls.keyStat.mtime != stat[1].mtime ||
|
||||
tls.keyStat.size != stat[1].size) {
|
||||
print("Reloading " + kCertificatePath + " and " + kPrivateKeyPath);
|
||||
var privateKey = utf8Decode(await File.readFile(kPrivateKeyPath));
|
||||
var certificate = utf8Decode(await File.readFile(kCertificatePath));
|
||||
let privateKey = utf8Decode(await File.readFile(kPrivateKeyPath));
|
||||
let certificate = utf8Decode(await File.readFile(kCertificatePath));
|
||||
|
||||
tls.context = new TlsContext();
|
||||
tls.context.setPrivateKey(privateKey);
|
||||
|
||||
7
deps/picohttpparser/.clang-format
vendored
Normal file
7
deps/picohttpparser/.clang-format
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
# requires clang-format >= 3.6
|
||||
BasedOnStyle: "LLVM"
|
||||
IndentWidth: 4
|
||||
ColumnLimit: 132
|
||||
BreakBeforeBraces: Linux
|
||||
AllowShortFunctionsOnASingleLine: None
|
||||
SortIncludes: false
|
||||
4
deps/picohttpparser/.gitignore
vendored
Normal file
4
deps/picohttpparser/.gitignore
vendored
Normal file
@@ -0,0 +1,4 @@
|
||||
test-bin
|
||||
xcuserdata
|
||||
*.xccheckout
|
||||
.DS_Store
|
||||
3
deps/picohttpparser/.gitmodules
vendored
Normal file
3
deps/picohttpparser/.gitmodules
vendored
Normal file
@@ -0,0 +1,3 @@
|
||||
[submodule "picotest"]
|
||||
path = picotest
|
||||
url = https://github.com/h2o/picotest.git
|
||||
6
deps/picohttpparser/.travis.yml
vendored
Normal file
6
deps/picohttpparser/.travis.yml
vendored
Normal file
@@ -0,0 +1,6 @@
|
||||
language: c
|
||||
compiler:
|
||||
- gcc
|
||||
- clang
|
||||
script:
|
||||
- make test
|
||||
7
deps/picohttpparser/Jamfile
vendored
Normal file
7
deps/picohttpparser/Jamfile
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
project picohttpparser ;
|
||||
|
||||
lib picohttpparser : picohttpparser.c ;
|
||||
|
||||
unit-test test
|
||||
: picohttpparser picotest/picotest.c test.c
|
||||
: <testing.launcher>prove ;
|
||||
40
deps/picohttpparser/Makefile
vendored
Normal file
40
deps/picohttpparser/Makefile
vendored
Normal file
@@ -0,0 +1,40 @@
|
||||
#
|
||||
# Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase,
|
||||
# Shigeo Mitsunari
|
||||
#
|
||||
# The software is licensed under either the MIT License (below) or the Perl
|
||||
# license.
|
||||
#
|
||||
# Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
# of this software and associated documentation files (the "Software"), to
|
||||
# deal in the Software without restriction, including without limitation the
|
||||
# rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
# sell copies of the Software, and to permit persons to whom the Software is
|
||||
# furnished to do so, subject to the following conditions:
|
||||
#
|
||||
# The above copyright notice and this permission notice shall be included in
|
||||
# all copies or substantial portions of the Software.
|
||||
#
|
||||
# THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
# IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
# FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
# AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
# LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
# FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
# IN THE SOFTWARE.
|
||||
|
||||
CC?=gcc
|
||||
PROVE?=prove
|
||||
|
||||
all:
|
||||
|
||||
test: test-bin
|
||||
$(PROVE) -v ./test-bin
|
||||
|
||||
test-bin: picohttpparser.c picotest/picotest.c test.c
|
||||
$(CC) -Wall $(CFLAGS) $(LDFLAGS) -o $@ $^
|
||||
|
||||
clean:
|
||||
rm -f test-bin
|
||||
|
||||
.PHONY: test
|
||||
116
deps/picohttpparser/README.md
vendored
Normal file
116
deps/picohttpparser/README.md
vendored
Normal file
@@ -0,0 +1,116 @@
|
||||
PicoHTTPParser
|
||||
=============
|
||||
|
||||
Copyright (c) 2009-2014 [Kazuho Oku](https://github.com/kazuho), [Tokuhiro Matsuno](https://github.com/tokuhirom), [Daisuke Murase](https://github.com/typester), [Shigeo Mitsunari](https://github.com/herumi)
|
||||
|
||||
PicoHTTPParser is a tiny, primitive, fast HTTP request/response parser.
|
||||
|
||||
Unlike most parsers, it is stateless and does not allocate memory by itself.
|
||||
All it does is accept pointer to buffer and the output structure, and setups the pointers in the latter to point at the necessary portions of the buffer.
|
||||
|
||||
The code is widely deployed within Perl applications through popular modules that use it, including [Plack](https://metacpan.org/pod/Plack), [Starman](https://metacpan.org/pod/Starman), [Starlet](https://metacpan.org/pod/Starlet), [Furl](https://metacpan.org/pod/Furl). It is also the HTTP/1 parser of [H2O](https://github.com/h2o/h2o).
|
||||
|
||||
Check out [test.c] to find out how to use the parser.
|
||||
|
||||
The software is dual-licensed under the Perl License or the MIT License.
|
||||
|
||||
Usage
|
||||
-----
|
||||
|
||||
The library exposes four functions: `phr_parse_request`, `phr_parse_response`, `phr_parse_headers`, `phr_decode_chunked`.
|
||||
|
||||
### phr_parse_request
|
||||
|
||||
The example below reads an HTTP request from socket `sock` using `read(2)`, parses it using `phr_parse_request`, and prints the details.
|
||||
|
||||
```c
|
||||
char buf[4096], *method, *path;
|
||||
int pret, minor_version;
|
||||
struct phr_header headers[100];
|
||||
size_t buflen = 0, prevbuflen = 0, method_len, path_len, num_headers;
|
||||
ssize_t rret;
|
||||
|
||||
while (1) {
|
||||
/* read the request */
|
||||
while ((rret = read(sock, buf + buflen, sizeof(buf) - buflen)) == -1 && errno == EINTR)
|
||||
;
|
||||
if (rret <= 0)
|
||||
return IOError;
|
||||
prevbuflen = buflen;
|
||||
buflen += rret;
|
||||
/* parse the request */
|
||||
num_headers = sizeof(headers) / sizeof(headers[0]);
|
||||
pret = phr_parse_request(buf, buflen, &method, &method_len, &path, &path_len,
|
||||
&minor_version, headers, &num_headers, prevbuflen);
|
||||
if (pret > 0)
|
||||
break; /* successfully parsed the request */
|
||||
else if (pret == -1)
|
||||
return ParseError;
|
||||
/* request is incomplete, continue the loop */
|
||||
assert(pret == -2);
|
||||
if (buflen == sizeof(buf))
|
||||
return RequestIsTooLongError;
|
||||
}
|
||||
|
||||
printf("request is %d bytes long\n", pret);
|
||||
printf("method is %.*s\n", (int)method_len, method);
|
||||
printf("path is %.*s\n", (int)path_len, path);
|
||||
printf("HTTP version is 1.%d\n", minor_version);
|
||||
printf("headers:\n");
|
||||
for (i = 0; i != num_headers; ++i) {
|
||||
printf("%.*s: %.*s\n", (int)headers[i].name_len, headers[i].name,
|
||||
(int)headers[i].value_len, headers[i].value);
|
||||
}
|
||||
```
|
||||
|
||||
### phr_parse_response, phr_parse_headers
|
||||
|
||||
`phr_parse_response` and `phr_parse_headers` provide similar interfaces as `phr_parse_request`. `phr_parse_response` parses an HTTP response, and `phr_parse_headers` parses the headers only.
|
||||
|
||||
### phr_decode_chunked
|
||||
|
||||
The example below decodes incoming data in chunked-encoding. The data is decoded in-place.
|
||||
|
||||
```c
|
||||
struct phr_chunked_decoder decoder = {}; /* zero-clear */
|
||||
char *buf = malloc(4096);
|
||||
size_t size = 0, capacity = 4096, rsize;
|
||||
ssize_t rret, pret;
|
||||
|
||||
/* set consume_trailer to 1 to discard the trailing header, or the application
|
||||
* should call phr_parse_headers to parse the trailing header */
|
||||
decoder.consume_trailer = 1;
|
||||
|
||||
do {
|
||||
/* expand the buffer if necessary */
|
||||
if (size == capacity) {
|
||||
capacity *= 2;
|
||||
buf = realloc(buf, capacity);
|
||||
assert(buf != NULL);
|
||||
}
|
||||
/* read */
|
||||
while ((rret = read(sock, buf + size, capacity - size)) == -1 && errno == EINTR)
|
||||
;
|
||||
if (rret <= 0)
|
||||
return IOError;
|
||||
/* decode */
|
||||
rsize = rret;
|
||||
pret = phr_decode_chunked(&decoder, buf + size, &rsize);
|
||||
if (pret == -1)
|
||||
return ParseError;
|
||||
size += rsize;
|
||||
} while (pret == -2);
|
||||
|
||||
/* successfully decoded the chunked data */
|
||||
assert(pret >= 0);
|
||||
printf("decoded data is at %p (%zu bytes)\n", buf, size);
|
||||
```
|
||||
|
||||
Benchmark
|
||||
---------
|
||||
|
||||
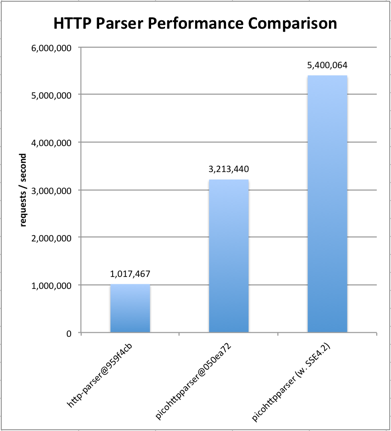
|
||||
|
||||
The benchmark code is from [fukamachi/fast-http@6b91103](https://github.com/fukamachi/fast-http/tree/6b9110347c7a3407310c08979aefd65078518478).
|
||||
|
||||
The internals of picohttpparser has been described to some extent in [my blog entry]( http://blog.kazuhooku.com/2014/11/the-internals-h2o-or-how-to-write-fast.html).
|
||||
66
deps/picohttpparser/bench.c
vendored
Normal file
66
deps/picohttpparser/bench.c
vendored
Normal file
@@ -0,0 +1,66 @@
|
||||
/*
|
||||
* Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase,
|
||||
* Shigeo Mitsunari
|
||||
*
|
||||
* The software is licensed under either the MIT License (below) or the Perl
|
||||
* license.
|
||||
*
|
||||
* Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
* of this software and associated documentation files (the "Software"), to
|
||||
* deal in the Software without restriction, including without limitation the
|
||||
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
* sell copies of the Software, and to permit persons to whom the Software is
|
||||
* furnished to do so, subject to the following conditions:
|
||||
*
|
||||
* The above copyright notice and this permission notice shall be included in
|
||||
* all copies or substantial portions of the Software.
|
||||
*
|
||||
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
* IN THE SOFTWARE.
|
||||
*/
|
||||
|
||||
#include <assert.h>
|
||||
#include <stdio.h>
|
||||
#include "picohttpparser.h"
|
||||
|
||||
#define REQ \
|
||||
"GET /wp-content/uploads/2010/03/hello-kitty-darth-vader-pink.jpg HTTP/1.1\r\n" \
|
||||
"Host: www.kittyhell.com\r\n" \
|
||||
"User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.6; ja-JP-mac; rv:1.9.2.3) Gecko/20100401 Firefox/3.6.3 " \
|
||||
"Pathtraq/0.9\r\n" \
|
||||
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\r\n" \
|
||||
"Accept-Language: ja,en-us;q=0.7,en;q=0.3\r\n" \
|
||||
"Accept-Encoding: gzip,deflate\r\n" \
|
||||
"Accept-Charset: Shift_JIS,utf-8;q=0.7,*;q=0.7\r\n" \
|
||||
"Keep-Alive: 115\r\n" \
|
||||
"Connection: keep-alive\r\n" \
|
||||
"Cookie: wp_ozh_wsa_visits=2; wp_ozh_wsa_visit_lasttime=xxxxxxxxxx; " \
|
||||
"__utma=xxxxxxxxx.xxxxxxxxxx.xxxxxxxxxx.xxxxxxxxxx.xxxxxxxxxx.x; " \
|
||||
"__utmz=xxxxxxxxx.xxxxxxxxxx.x.x.utmccn=(referral)|utmcsr=reader.livedoor.com|utmcct=/reader/|utmcmd=referral\r\n" \
|
||||
"\r\n"
|
||||
|
||||
int main(void)
|
||||
{
|
||||
const char *method;
|
||||
size_t method_len;
|
||||
const char *path;
|
||||
size_t path_len;
|
||||
int minor_version;
|
||||
struct phr_header headers[32];
|
||||
size_t num_headers;
|
||||
int i, ret;
|
||||
|
||||
for (i = 0; i < 10000000; i++) {
|
||||
num_headers = sizeof(headers) / sizeof(headers[0]);
|
||||
ret = phr_parse_request(REQ, sizeof(REQ) - 1, &method, &method_len, &path, &path_len, &minor_version, headers, &num_headers,
|
||||
0);
|
||||
assert(ret == sizeof(REQ) - 1);
|
||||
}
|
||||
|
||||
return 0;
|
||||
}
|
||||
665
deps/picohttpparser/picohttpparser.c
vendored
Normal file
665
deps/picohttpparser/picohttpparser.c
vendored
Normal file
@@ -0,0 +1,665 @@
|
||||
/*
|
||||
* Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase,
|
||||
* Shigeo Mitsunari
|
||||
*
|
||||
* The software is licensed under either the MIT License (below) or the Perl
|
||||
* license.
|
||||
*
|
||||
* Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
* of this software and associated documentation files (the "Software"), to
|
||||
* deal in the Software without restriction, including without limitation the
|
||||
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
* sell copies of the Software, and to permit persons to whom the Software is
|
||||
* furnished to do so, subject to the following conditions:
|
||||
*
|
||||
* The above copyright notice and this permission notice shall be included in
|
||||
* all copies or substantial portions of the Software.
|
||||
*
|
||||
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
* IN THE SOFTWARE.
|
||||
*/
|
||||
|
||||
#include <assert.h>
|
||||
#include <stddef.h>
|
||||
#include <string.h>
|
||||
#ifdef __SSE4_2__
|
||||
#ifdef _MSC_VER
|
||||
#include <nmmintrin.h>
|
||||
#else
|
||||
#include <x86intrin.h>
|
||||
#endif
|
||||
#endif
|
||||
#include "picohttpparser.h"
|
||||
|
||||
#if __GNUC__ >= 3
|
||||
#define likely(x) __builtin_expect(!!(x), 1)
|
||||
#define unlikely(x) __builtin_expect(!!(x), 0)
|
||||
#else
|
||||
#define likely(x) (x)
|
||||
#define unlikely(x) (x)
|
||||
#endif
|
||||
|
||||
#ifdef _MSC_VER
|
||||
#define ALIGNED(n) _declspec(align(n))
|
||||
#else
|
||||
#define ALIGNED(n) __attribute__((aligned(n)))
|
||||
#endif
|
||||
|
||||
#define IS_PRINTABLE_ASCII(c) ((unsigned char)(c)-040u < 0137u)
|
||||
|
||||
#define CHECK_EOF() \
|
||||
if (buf == buf_end) { \
|
||||
*ret = -2; \
|
||||
return NULL; \
|
||||
}
|
||||
|
||||
#define EXPECT_CHAR_NO_CHECK(ch) \
|
||||
if (*buf++ != ch) { \
|
||||
*ret = -1; \
|
||||
return NULL; \
|
||||
}
|
||||
|
||||
#define EXPECT_CHAR(ch) \
|
||||
CHECK_EOF(); \
|
||||
EXPECT_CHAR_NO_CHECK(ch);
|
||||
|
||||
#define ADVANCE_TOKEN(tok, toklen) \
|
||||
do { \
|
||||
const char *tok_start = buf; \
|
||||
static const char ALIGNED(16) ranges2[16] = "\000\040\177\177"; \
|
||||
int found2; \
|
||||
buf = findchar_fast(buf, buf_end, ranges2, 4, &found2); \
|
||||
if (!found2) { \
|
||||
CHECK_EOF(); \
|
||||
} \
|
||||
while (1) { \
|
||||
if (*buf == ' ') { \
|
||||
break; \
|
||||
} else if (unlikely(!IS_PRINTABLE_ASCII(*buf))) { \
|
||||
if ((unsigned char)*buf < '\040' || *buf == '\177') { \
|
||||
*ret = -1; \
|
||||
return NULL; \
|
||||
} \
|
||||
} \
|
||||
++buf; \
|
||||
CHECK_EOF(); \
|
||||
} \
|
||||
tok = tok_start; \
|
||||
toklen = buf - tok_start; \
|
||||
} while (0)
|
||||
|
||||
static const char *token_char_map = "\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
||||
"\0\1\0\1\1\1\1\1\0\0\1\1\0\1\1\0\1\1\1\1\1\1\1\1\1\1\0\0\0\0\0\0"
|
||||
"\0\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\0\0\0\1\1"
|
||||
"\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\1\0\1\0\1\0"
|
||||
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
||||
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
||||
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"
|
||||
"\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0";
|
||||
|
||||
static const char *findchar_fast(const char *buf, const char *buf_end, const char *ranges, size_t ranges_size, int *found)
|
||||
{
|
||||
*found = 0;
|
||||
#if __SSE4_2__
|
||||
if (likely(buf_end - buf >= 16)) {
|
||||
__m128i ranges16 = _mm_loadu_si128((const __m128i *)ranges);
|
||||
|
||||
size_t left = (buf_end - buf) & ~15;
|
||||
do {
|
||||
__m128i b16 = _mm_loadu_si128((const __m128i *)buf);
|
||||
int r = _mm_cmpestri(ranges16, ranges_size, b16, 16, _SIDD_LEAST_SIGNIFICANT | _SIDD_CMP_RANGES | _SIDD_UBYTE_OPS);
|
||||
if (unlikely(r != 16)) {
|
||||
buf += r;
|
||||
*found = 1;
|
||||
break;
|
||||
}
|
||||
buf += 16;
|
||||
left -= 16;
|
||||
} while (likely(left != 0));
|
||||
}
|
||||
#else
|
||||
/* suppress unused parameter warning */
|
||||
(void)buf_end;
|
||||
(void)ranges;
|
||||
(void)ranges_size;
|
||||
#endif
|
||||
return buf;
|
||||
}
|
||||
|
||||
static const char *get_token_to_eol(const char *buf, const char *buf_end, const char **token, size_t *token_len, int *ret)
|
||||
{
|
||||
const char *token_start = buf;
|
||||
|
||||
#ifdef __SSE4_2__
|
||||
static const char ALIGNED(16) ranges1[16] = "\0\010" /* allow HT */
|
||||
"\012\037" /* allow SP and up to but not including DEL */
|
||||
"\177\177"; /* allow chars w. MSB set */
|
||||
int found;
|
||||
buf = findchar_fast(buf, buf_end, ranges1, 6, &found);
|
||||
if (found)
|
||||
goto FOUND_CTL;
|
||||
#else
|
||||
/* find non-printable char within the next 8 bytes, this is the hottest code; manually inlined */
|
||||
while (likely(buf_end - buf >= 8)) {
|
||||
#define DOIT() \
|
||||
do { \
|
||||
if (unlikely(!IS_PRINTABLE_ASCII(*buf))) \
|
||||
goto NonPrintable; \
|
||||
++buf; \
|
||||
} while (0)
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
DOIT();
|
||||
#undef DOIT
|
||||
continue;
|
||||
NonPrintable:
|
||||
if ((likely((unsigned char)*buf < '\040') && likely(*buf != '\011')) || unlikely(*buf == '\177')) {
|
||||
goto FOUND_CTL;
|
||||
}
|
||||
++buf;
|
||||
}
|
||||
#endif
|
||||
for (;; ++buf) {
|
||||
CHECK_EOF();
|
||||
if (unlikely(!IS_PRINTABLE_ASCII(*buf))) {
|
||||
if ((likely((unsigned char)*buf < '\040') && likely(*buf != '\011')) || unlikely(*buf == '\177')) {
|
||||
goto FOUND_CTL;
|
||||
}
|
||||
}
|
||||
}
|
||||
FOUND_CTL:
|
||||
if (likely(*buf == '\015')) {
|
||||
++buf;
|
||||
EXPECT_CHAR('\012');
|
||||
*token_len = buf - 2 - token_start;
|
||||
} else if (*buf == '\012') {
|
||||
*token_len = buf - token_start;
|
||||
++buf;
|
||||
} else {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
*token = token_start;
|
||||
|
||||
return buf;
|
||||
}
|
||||
|
||||
static const char *is_complete(const char *buf, const char *buf_end, size_t last_len, int *ret)
|
||||
{
|
||||
int ret_cnt = 0;
|
||||
buf = last_len < 3 ? buf : buf + last_len - 3;
|
||||
|
||||
while (1) {
|
||||
CHECK_EOF();
|
||||
if (*buf == '\015') {
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
EXPECT_CHAR('\012');
|
||||
++ret_cnt;
|
||||
} else if (*buf == '\012') {
|
||||
++buf;
|
||||
++ret_cnt;
|
||||
} else {
|
||||
++buf;
|
||||
ret_cnt = 0;
|
||||
}
|
||||
if (ret_cnt == 2) {
|
||||
return buf;
|
||||
}
|
||||
}
|
||||
|
||||
*ret = -2;
|
||||
return NULL;
|
||||
}
|
||||
|
||||
#define PARSE_INT(valp_, mul_) \
|
||||
if (*buf < '0' || '9' < *buf) { \
|
||||
buf++; \
|
||||
*ret = -1; \
|
||||
return NULL; \
|
||||
} \
|
||||
*(valp_) = (mul_) * (*buf++ - '0');
|
||||
|
||||
#define PARSE_INT_3(valp_) \
|
||||
do { \
|
||||
int res_ = 0; \
|
||||
PARSE_INT(&res_, 100) \
|
||||
*valp_ = res_; \
|
||||
PARSE_INT(&res_, 10) \
|
||||
*valp_ += res_; \
|
||||
PARSE_INT(&res_, 1) \
|
||||
*valp_ += res_; \
|
||||
} while (0)
|
||||
|
||||
/* returned pointer is always within [buf, buf_end), or null */
|
||||
static const char *parse_token(const char *buf, const char *buf_end, const char **token, size_t *token_len, char next_char,
|
||||
int *ret)
|
||||
{
|
||||
/* We use pcmpestri to detect non-token characters. This instruction can take no more than eight character ranges (8*2*8=128
|
||||
* bits that is the size of a SSE register). Due to this restriction, characters `|` and `~` are handled in the slow loop. */
|
||||
static const char ALIGNED(16) ranges[] = "\x00 " /* control chars and up to SP */
|
||||
"\"\"" /* 0x22 */
|
||||
"()" /* 0x28,0x29 */
|
||||
",," /* 0x2c */
|
||||
"//" /* 0x2f */
|
||||
":@" /* 0x3a-0x40 */
|
||||
"[]" /* 0x5b-0x5d */
|
||||
"{\xff"; /* 0x7b-0xff */
|
||||
const char *buf_start = buf;
|
||||
int found;
|
||||
buf = findchar_fast(buf, buf_end, ranges, sizeof(ranges) - 1, &found);
|
||||
if (!found) {
|
||||
CHECK_EOF();
|
||||
}
|
||||
while (1) {
|
||||
if (*buf == next_char) {
|
||||
break;
|
||||
} else if (!token_char_map[(unsigned char)*buf]) {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
}
|
||||
*token = buf_start;
|
||||
*token_len = buf - buf_start;
|
||||
return buf;
|
||||
}
|
||||
|
||||
/* returned pointer is always within [buf, buf_end), or null */
|
||||
static const char *parse_http_version(const char *buf, const char *buf_end, int *minor_version, int *ret)
|
||||
{
|
||||
/* we want at least [HTTP/1.<two chars>] to try to parse */
|
||||
if (buf_end - buf < 9) {
|
||||
*ret = -2;
|
||||
return NULL;
|
||||
}
|
||||
EXPECT_CHAR_NO_CHECK('H');
|
||||
EXPECT_CHAR_NO_CHECK('T');
|
||||
EXPECT_CHAR_NO_CHECK('T');
|
||||
EXPECT_CHAR_NO_CHECK('P');
|
||||
EXPECT_CHAR_NO_CHECK('/');
|
||||
EXPECT_CHAR_NO_CHECK('1');
|
||||
EXPECT_CHAR_NO_CHECK('.');
|
||||
PARSE_INT(minor_version, 1);
|
||||
return buf;
|
||||
}
|
||||
|
||||
static const char *parse_headers(const char *buf, const char *buf_end, struct phr_header *headers, size_t *num_headers,
|
||||
size_t max_headers, int *ret)
|
||||
{
|
||||
for (;; ++*num_headers) {
|
||||
CHECK_EOF();
|
||||
if (*buf == '\015') {
|
||||
++buf;
|
||||
EXPECT_CHAR('\012');
|
||||
break;
|
||||
} else if (*buf == '\012') {
|
||||
++buf;
|
||||
break;
|
||||
}
|
||||
if (*num_headers == max_headers) {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
if (!(*num_headers != 0 && (*buf == ' ' || *buf == '\t'))) {
|
||||
/* parsing name, but do not discard SP before colon, see
|
||||
* http://www.mozilla.org/security/announce/2006/mfsa2006-33.html */
|
||||
if ((buf = parse_token(buf, buf_end, &headers[*num_headers].name, &headers[*num_headers].name_len, ':', ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
if (headers[*num_headers].name_len == 0) {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
++buf;
|
||||
for (;; ++buf) {
|
||||
CHECK_EOF();
|
||||
if (!(*buf == ' ' || *buf == '\t')) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
} else {
|
||||
headers[*num_headers].name = NULL;
|
||||
headers[*num_headers].name_len = 0;
|
||||
}
|
||||
const char *value;
|
||||
size_t value_len;
|
||||
if ((buf = get_token_to_eol(buf, buf_end, &value, &value_len, ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
/* remove trailing SPs and HTABs */
|
||||
const char *value_end = value + value_len;
|
||||
for (; value_end != value; --value_end) {
|
||||
const char c = *(value_end - 1);
|
||||
if (!(c == ' ' || c == '\t')) {
|
||||
break;
|
||||
}
|
||||
}
|
||||
headers[*num_headers].value = value;
|
||||
headers[*num_headers].value_len = value_end - value;
|
||||
}
|
||||
return buf;
|
||||
}
|
||||
|
||||
static const char *parse_request(const char *buf, const char *buf_end, const char **method, size_t *method_len, const char **path,
|
||||
size_t *path_len, int *minor_version, struct phr_header *headers, size_t *num_headers,
|
||||
size_t max_headers, int *ret)
|
||||
{
|
||||
/* skip first empty line (some clients add CRLF after POST content) */
|
||||
CHECK_EOF();
|
||||
if (*buf == '\015') {
|
||||
++buf;
|
||||
EXPECT_CHAR('\012');
|
||||
} else if (*buf == '\012') {
|
||||
++buf;
|
||||
}
|
||||
|
||||
/* parse request line */
|
||||
if ((buf = parse_token(buf, buf_end, method, method_len, ' ', ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
do {
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
} while (*buf == ' ');
|
||||
ADVANCE_TOKEN(*path, *path_len);
|
||||
do {
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
} while (*buf == ' ');
|
||||
if (*method_len == 0 || *path_len == 0) {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
if ((buf = parse_http_version(buf, buf_end, minor_version, ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
if (*buf == '\015') {
|
||||
++buf;
|
||||
EXPECT_CHAR('\012');
|
||||
} else if (*buf == '\012') {
|
||||
++buf;
|
||||
} else {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
|
||||
return parse_headers(buf, buf_end, headers, num_headers, max_headers, ret);
|
||||
}
|
||||
|
||||
int phr_parse_request(const char *buf_start, size_t len, const char **method, size_t *method_len, const char **path,
|
||||
size_t *path_len, int *minor_version, struct phr_header *headers, size_t *num_headers, size_t last_len)
|
||||
{
|
||||
const char *buf = buf_start, *buf_end = buf_start + len;
|
||||
size_t max_headers = *num_headers;
|
||||
int r;
|
||||
|
||||
*method = NULL;
|
||||
*method_len = 0;
|
||||
*path = NULL;
|
||||
*path_len = 0;
|
||||
*minor_version = -1;
|
||||
*num_headers = 0;
|
||||
|
||||
/* if last_len != 0, check if the request is complete (a fast countermeasure
|
||||
againt slowloris */
|
||||
if (last_len != 0 && is_complete(buf, buf_end, last_len, &r) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
if ((buf = parse_request(buf, buf_end, method, method_len, path, path_len, minor_version, headers, num_headers, max_headers,
|
||||
&r)) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
return (int)(buf - buf_start);
|
||||
}
|
||||
|
||||
static const char *parse_response(const char *buf, const char *buf_end, int *minor_version, int *status, const char **msg,
|
||||
size_t *msg_len, struct phr_header *headers, size_t *num_headers, size_t max_headers, int *ret)
|
||||
{
|
||||
/* parse "HTTP/1.x" */
|
||||
if ((buf = parse_http_version(buf, buf_end, minor_version, ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
/* skip space */
|
||||
if (*buf != ' ') {
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
do {
|
||||
++buf;
|
||||
CHECK_EOF();
|
||||
} while (*buf == ' ');
|
||||
/* parse status code, we want at least [:digit:][:digit:][:digit:]<other char> to try to parse */
|
||||
if (buf_end - buf < 4) {
|
||||
*ret = -2;
|
||||
return NULL;
|
||||
}
|
||||
PARSE_INT_3(status);
|
||||
|
||||
/* get message including preceding space */
|
||||
if ((buf = get_token_to_eol(buf, buf_end, msg, msg_len, ret)) == NULL) {
|
||||
return NULL;
|
||||
}
|
||||
if (*msg_len == 0) {
|
||||
/* ok */
|
||||
} else if (**msg == ' ') {
|
||||
/* Remove preceding space. Successful return from `get_token_to_eol` guarantees that we would hit something other than SP
|
||||
* before running past the end of the given buffer. */
|
||||
do {
|
||||
++*msg;
|
||||
--*msg_len;
|
||||
} while (**msg == ' ');
|
||||
} else {
|
||||
/* garbage found after status code */
|
||||
*ret = -1;
|
||||
return NULL;
|
||||
}
|
||||
|
||||
return parse_headers(buf, buf_end, headers, num_headers, max_headers, ret);
|
||||
}
|
||||
|
||||
int phr_parse_response(const char *buf_start, size_t len, int *minor_version, int *status, const char **msg, size_t *msg_len,
|
||||
struct phr_header *headers, size_t *num_headers, size_t last_len)
|
||||
{
|
||||
const char *buf = buf_start, *buf_end = buf + len;
|
||||
size_t max_headers = *num_headers;
|
||||
int r;
|
||||
|
||||
*minor_version = -1;
|
||||
*status = 0;
|
||||
*msg = NULL;
|
||||
*msg_len = 0;
|
||||
*num_headers = 0;
|
||||
|
||||
/* if last_len != 0, check if the response is complete (a fast countermeasure
|
||||
against slowloris */
|
||||
if (last_len != 0 && is_complete(buf, buf_end, last_len, &r) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
if ((buf = parse_response(buf, buf_end, minor_version, status, msg, msg_len, headers, num_headers, max_headers, &r)) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
return (int)(buf - buf_start);
|
||||
}
|
||||
|
||||
int phr_parse_headers(const char *buf_start, size_t len, struct phr_header *headers, size_t *num_headers, size_t last_len)
|
||||
{
|
||||
const char *buf = buf_start, *buf_end = buf + len;
|
||||
size_t max_headers = *num_headers;
|
||||
int r;
|
||||
|
||||
*num_headers = 0;
|
||||
|
||||
/* if last_len != 0, check if the response is complete (a fast countermeasure
|
||||
against slowloris */
|
||||
if (last_len != 0 && is_complete(buf, buf_end, last_len, &r) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
if ((buf = parse_headers(buf, buf_end, headers, num_headers, max_headers, &r)) == NULL) {
|
||||
return r;
|
||||
}
|
||||
|
||||
return (int)(buf - buf_start);
|
||||
}
|
||||
|
||||
enum {
|
||||
CHUNKED_IN_CHUNK_SIZE,
|
||||
CHUNKED_IN_CHUNK_EXT,
|
||||
CHUNKED_IN_CHUNK_DATA,
|
||||
CHUNKED_IN_CHUNK_CRLF,
|
||||
CHUNKED_IN_TRAILERS_LINE_HEAD,
|
||||
CHUNKED_IN_TRAILERS_LINE_MIDDLE
|
||||
};
|
||||
|
||||
static int decode_hex(int ch)
|
||||
{
|
||||
if ('0' <= ch && ch <= '9') {
|
||||
return ch - '0';
|
||||
} else if ('A' <= ch && ch <= 'F') {
|
||||
return ch - 'A' + 0xa;
|
||||
} else if ('a' <= ch && ch <= 'f') {
|
||||
return ch - 'a' + 0xa;
|
||||
} else {
|
||||
return -1;
|
||||
}
|
||||
}
|
||||
|
||||
ssize_t phr_decode_chunked(struct phr_chunked_decoder *decoder, char *buf, size_t *_bufsz)
|
||||
{
|
||||
size_t dst = 0, src = 0, bufsz = *_bufsz;
|
||||
ssize_t ret = -2; /* incomplete */
|
||||
|
||||
while (1) {
|
||||
switch (decoder->_state) {
|
||||
case CHUNKED_IN_CHUNK_SIZE:
|
||||
for (;; ++src) {
|
||||
int v;
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if ((v = decode_hex(buf[src])) == -1) {
|
||||
if (decoder->_hex_count == 0) {
|
||||
ret = -1;
|
||||
goto Exit;
|
||||
}
|
||||
break;
|
||||
}
|
||||
if (decoder->_hex_count == sizeof(size_t) * 2) {
|
||||
ret = -1;
|
||||
goto Exit;
|
||||
}
|
||||
decoder->bytes_left_in_chunk = decoder->bytes_left_in_chunk * 16 + v;
|
||||
++decoder->_hex_count;
|
||||
}
|
||||
decoder->_hex_count = 0;
|
||||
decoder->_state = CHUNKED_IN_CHUNK_EXT;
|
||||
/* fallthru */
|
||||
case CHUNKED_IN_CHUNK_EXT:
|
||||
/* RFC 7230 A.2 "Line folding in chunk extensions is disallowed" */
|
||||
for (;; ++src) {
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if (buf[src] == '\012')
|
||||
break;
|
||||
}
|
||||
++src;
|
||||
if (decoder->bytes_left_in_chunk == 0) {
|
||||
if (decoder->consume_trailer) {
|
||||
decoder->_state = CHUNKED_IN_TRAILERS_LINE_HEAD;
|
||||
break;
|
||||
} else {
|
||||
goto Complete;
|
||||
}
|
||||
}
|
||||
decoder->_state = CHUNKED_IN_CHUNK_DATA;
|
||||
/* fallthru */
|
||||
case CHUNKED_IN_CHUNK_DATA: {
|
||||
size_t avail = bufsz - src;
|
||||
if (avail < decoder->bytes_left_in_chunk) {
|
||||
if (dst != src)
|
||||
memmove(buf + dst, buf + src, avail);
|
||||
src += avail;
|
||||
dst += avail;
|
||||
decoder->bytes_left_in_chunk -= avail;
|
||||
goto Exit;
|
||||
}
|
||||
if (dst != src)
|
||||
memmove(buf + dst, buf + src, decoder->bytes_left_in_chunk);
|
||||
src += decoder->bytes_left_in_chunk;
|
||||
dst += decoder->bytes_left_in_chunk;
|
||||
decoder->bytes_left_in_chunk = 0;
|
||||
decoder->_state = CHUNKED_IN_CHUNK_CRLF;
|
||||
}
|
||||
/* fallthru */
|
||||
case CHUNKED_IN_CHUNK_CRLF:
|
||||
for (;; ++src) {
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if (buf[src] != '\015')
|
||||
break;
|
||||
}
|
||||
if (buf[src] != '\012') {
|
||||
ret = -1;
|
||||
goto Exit;
|
||||
}
|
||||
++src;
|
||||
decoder->_state = CHUNKED_IN_CHUNK_SIZE;
|
||||
break;
|
||||
case CHUNKED_IN_TRAILERS_LINE_HEAD:
|
||||
for (;; ++src) {
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if (buf[src] != '\015')
|
||||
break;
|
||||
}
|
||||
if (buf[src++] == '\012')
|
||||
goto Complete;
|
||||
decoder->_state = CHUNKED_IN_TRAILERS_LINE_MIDDLE;
|
||||
/* fallthru */
|
||||
case CHUNKED_IN_TRAILERS_LINE_MIDDLE:
|
||||
for (;; ++src) {
|
||||
if (src == bufsz)
|
||||
goto Exit;
|
||||
if (buf[src] == '\012')
|
||||
break;
|
||||
}
|
||||
++src;
|
||||
decoder->_state = CHUNKED_IN_TRAILERS_LINE_HEAD;
|
||||
break;
|
||||
default:
|
||||
assert(!"decoder is corrupt");
|
||||
}
|
||||
}
|
||||
|
||||
Complete:
|
||||
ret = bufsz - src;
|
||||
Exit:
|
||||
if (dst != src)
|
||||
memmove(buf + dst, buf + src, bufsz - src);
|
||||
*_bufsz = dst;
|
||||
return ret;
|
||||
}
|
||||
|
||||
int phr_decode_chunked_is_in_data(struct phr_chunked_decoder *decoder)
|
||||
{
|
||||
return decoder->_state == CHUNKED_IN_CHUNK_DATA;
|
||||
}
|
||||
|
||||
#undef CHECK_EOF
|
||||
#undef EXPECT_CHAR
|
||||
#undef ADVANCE_TOKEN
|
||||
87
deps/picohttpparser/picohttpparser.h
vendored
Normal file
87
deps/picohttpparser/picohttpparser.h
vendored
Normal file
@@ -0,0 +1,87 @@
|
||||
/*
|
||||
* Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase,
|
||||
* Shigeo Mitsunari
|
||||
*
|
||||
* The software is licensed under either the MIT License (below) or the Perl
|
||||
* license.
|
||||
*
|
||||
* Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
* of this software and associated documentation files (the "Software"), to
|
||||
* deal in the Software without restriction, including without limitation the
|
||||
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
* sell copies of the Software, and to permit persons to whom the Software is
|
||||
* furnished to do so, subject to the following conditions:
|
||||
*
|
||||
* The above copyright notice and this permission notice shall be included in
|
||||
* all copies or substantial portions of the Software.
|
||||
*
|
||||
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
* IN THE SOFTWARE.
|
||||
*/
|
||||
|
||||
#ifndef picohttpparser_h
|
||||
#define picohttpparser_h
|
||||
|
||||
#include <sys/types.h>
|
||||
|
||||
#ifdef _MSC_VER
|
||||
#define ssize_t intptr_t
|
||||
#endif
|
||||
|
||||
#ifdef __cplusplus
|
||||
extern "C" {
|
||||
#endif
|
||||
|
||||
/* contains name and value of a header (name == NULL if is a continuing line
|
||||
* of a multiline header */
|
||||
struct phr_header {
|
||||
const char *name;
|
||||
size_t name_len;
|
||||
const char *value;
|
||||
size_t value_len;
|
||||
};
|
||||
|
||||
/* returns number of bytes consumed if successful, -2 if request is partial,
|
||||
* -1 if failed */
|
||||
int phr_parse_request(const char *buf, size_t len, const char **method, size_t *method_len, const char **path, size_t *path_len,
|
||||
int *minor_version, struct phr_header *headers, size_t *num_headers, size_t last_len);
|
||||
|
||||
/* ditto */
|
||||
int phr_parse_response(const char *_buf, size_t len, int *minor_version, int *status, const char **msg, size_t *msg_len,
|
||||
struct phr_header *headers, size_t *num_headers, size_t last_len);
|
||||
|
||||
/* ditto */
|
||||
int phr_parse_headers(const char *buf, size_t len, struct phr_header *headers, size_t *num_headers, size_t last_len);
|
||||
|
||||
/* should be zero-filled before start */
|
||||
struct phr_chunked_decoder {
|
||||
size_t bytes_left_in_chunk; /* number of bytes left in current chunk */
|
||||
char consume_trailer; /* if trailing headers should be consumed */
|
||||
char _hex_count;
|
||||
char _state;
|
||||
};
|
||||
|
||||
/* the function rewrites the buffer given as (buf, bufsz) removing the chunked-
|
||||
* encoding headers. When the function returns without an error, bufsz is
|
||||
* updated to the length of the decoded data available. Applications should
|
||||
* repeatedly call the function while it returns -2 (incomplete) every time
|
||||
* supplying newly arrived data. If the end of the chunked-encoded data is
|
||||
* found, the function returns a non-negative number indicating the number of
|
||||
* octets left undecoded, that starts from the offset returned by `*bufsz`.
|
||||
* Returns -1 on error.
|
||||
*/
|
||||
ssize_t phr_decode_chunked(struct phr_chunked_decoder *decoder, char *buf, size_t *bufsz);
|
||||
|
||||
/* returns if the chunked decoder is in middle of chunked data */
|
||||
int phr_decode_chunked_is_in_data(struct phr_chunked_decoder *decoder);
|
||||
|
||||
#ifdef __cplusplus
|
||||
}
|
||||
#endif
|
||||
|
||||
#endif
|
||||
290
deps/picohttpparser/picohttpparser.xcodeproj/project.pbxproj
vendored
Normal file
290
deps/picohttpparser/picohttpparser.xcodeproj/project.pbxproj
vendored
Normal file
@@ -0,0 +1,290 @@
|
||||
// !$*UTF8*$!
|
||||
{
|
||||
archiveVersion = 1;
|
||||
classes = {
|
||||
};
|
||||
objectVersion = 50;
|
||||
objects = {
|
||||
|
||||
/* Begin PBXBuildFile section */
|
||||
E98BADCF24BBFCA10040C7D4 /* picohttpparser.c in Sources */ = {isa = PBXBuildFile; fileRef = E98BADCD24BBFCA10040C7D4 /* picohttpparser.c */; };
|
||||
E98BADD024BBFCA10040C7D4 /* test.c in Sources */ = {isa = PBXBuildFile; fileRef = E98BADCE24BBFCA10040C7D4 /* test.c */; };
|
||||
E98BADD424BBFCB40040C7D4 /* picotest.c in Sources */ = {isa = PBXBuildFile; fileRef = E98BADD224BBFCB40040C7D4 /* picotest.c */; };
|
||||
/* End PBXBuildFile section */
|
||||
|
||||
/* Begin PBXCopyFilesBuildPhase section */
|
||||
E98BADC024BBFC4E0040C7D4 /* CopyFiles */ = {
|
||||
isa = PBXCopyFilesBuildPhase;
|
||||
buildActionMask = 2147483647;
|
||||
dstPath = /usr/share/man/man1/;
|
||||
dstSubfolderSpec = 0;
|
||||
files = (
|
||||
);
|
||||
runOnlyForDeploymentPostprocessing = 1;
|
||||
};
|
||||
/* End PBXCopyFilesBuildPhase section */
|
||||
|
||||
/* Begin PBXFileReference section */
|
||||
E98BADC224BBFC4E0040C7D4 /* test */ = {isa = PBXFileReference; explicitFileType = "compiled.mach-o.executable"; includeInIndex = 0; path = test; sourceTree = BUILT_PRODUCTS_DIR; };
|
||||
E98BADCC24BBFCA10040C7D4 /* picohttpparser.h */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.h; path = picohttpparser.h; sourceTree = "<group>"; };
|
||||
E98BADCD24BBFCA10040C7D4 /* picohttpparser.c */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.c; path = picohttpparser.c; sourceTree = "<group>"; };
|
||||
E98BADCE24BBFCA10040C7D4 /* test.c */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.c; path = test.c; sourceTree = "<group>"; };
|
||||
E98BADD224BBFCB40040C7D4 /* picotest.c */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.c; path = picotest.c; sourceTree = "<group>"; };
|
||||
E98BADD324BBFCB40040C7D4 /* picotest.h */ = {isa = PBXFileReference; fileEncoding = 4; lastKnownFileType = sourcecode.c.h; path = picotest.h; sourceTree = "<group>"; };
|
||||
/* End PBXFileReference section */
|
||||
|
||||
/* Begin PBXFrameworksBuildPhase section */
|
||||
E98BADBF24BBFC4E0040C7D4 /* Frameworks */ = {
|
||||
isa = PBXFrameworksBuildPhase;
|
||||
buildActionMask = 2147483647;
|
||||
files = (
|
||||
);
|
||||
runOnlyForDeploymentPostprocessing = 0;
|
||||
};
|
||||
/* End PBXFrameworksBuildPhase section */
|
||||
|
||||
/* Begin PBXGroup section */
|
||||
E98BADB924BBFC4E0040C7D4 = {
|
||||
isa = PBXGroup;
|
||||
children = (
|
||||
E98BADD124BBFCA50040C7D4 /* picotest */,
|
||||
E98BADCD24BBFCA10040C7D4 /* picohttpparser.c */,
|
||||
E98BADCC24BBFCA10040C7D4 /* picohttpparser.h */,
|
||||
E98BADCE24BBFCA10040C7D4 /* test.c */,
|
||||
E98BADC324BBFC4E0040C7D4 /* Products */,
|
||||
);
|
||||
sourceTree = "<group>";
|
||||
};
|
||||
E98BADC324BBFC4E0040C7D4 /* Products */ = {
|
||||
isa = PBXGroup;
|
||||
children = (
|
||||
E98BADC224BBFC4E0040C7D4 /* test */,
|
||||
);
|
||||
name = Products;
|
||||
sourceTree = "<group>";
|
||||
};
|
||||
E98BADD124BBFCA50040C7D4 /* picotest */ = {
|
||||
isa = PBXGroup;
|
||||
children = (
|
||||
E98BADD224BBFCB40040C7D4 /* picotest.c */,
|
||||
E98BADD324BBFCB40040C7D4 /* picotest.h */,
|
||||
);
|
||||
path = picotest;
|
||||
sourceTree = "<group>";
|
||||
};
|
||||
/* End PBXGroup section */
|
||||
|
||||
/* Begin PBXNativeTarget section */
|
||||
E98BADC124BBFC4E0040C7D4 /* test */ = {
|
||||
isa = PBXNativeTarget;
|
||||
buildConfigurationList = E98BADC924BBFC4E0040C7D4 /* Build configuration list for PBXNativeTarget "test" */;
|
||||
buildPhases = (
|
||||
E98BADBE24BBFC4E0040C7D4 /* Sources */,
|
||||
E98BADBF24BBFC4E0040C7D4 /* Frameworks */,
|
||||
E98BADC024BBFC4E0040C7D4 /* CopyFiles */,
|
||||
);
|
||||
buildRules = (
|
||||
);
|
||||
dependencies = (
|
||||
);
|
||||
name = test;
|
||||
productName = picohttpparser;
|
||||
productReference = E98BADC224BBFC4E0040C7D4 /* test */;
|
||||
productType = "com.apple.product-type.tool";
|
||||
};
|
||||
/* End PBXNativeTarget section */
|
||||
|
||||
/* Begin PBXProject section */
|
||||
E98BADBA24BBFC4E0040C7D4 /* Project object */ = {
|
||||
isa = PBXProject;
|
||||
attributes = {
|
||||
LastUpgradeCheck = 1150;
|
||||
ORGANIZATIONNAME = H2O;
|
||||
TargetAttributes = {
|
||||
E98BADC124BBFC4E0040C7D4 = {
|
||||
CreatedOnToolsVersion = 11.5;
|
||||
};
|
||||
};
|
||||
};
|
||||
buildConfigurationList = E98BADBD24BBFC4E0040C7D4 /* Build configuration list for PBXProject "picohttpparser" */;
|
||||
compatibilityVersion = "Xcode 9.3";
|
||||
developmentRegion = en;
|
||||
hasScannedForEncodings = 0;
|
||||
knownRegions = (
|
||||
en,
|
||||
Base,
|
||||
);
|
||||
mainGroup = E98BADB924BBFC4E0040C7D4;
|
||||
productRefGroup = E98BADC324BBFC4E0040C7D4 /* Products */;
|
||||
projectDirPath = "";
|
||||
projectRoot = "";
|
||||
targets = (
|
||||
E98BADC124BBFC4E0040C7D4 /* test */,
|
||||
);
|
||||
};
|
||||
/* End PBXProject section */
|
||||
|
||||
/* Begin PBXSourcesBuildPhase section */
|
||||
E98BADBE24BBFC4E0040C7D4 /* Sources */ = {
|
||||
isa = PBXSourcesBuildPhase;
|
||||
buildActionMask = 2147483647;
|
||||
files = (
|
||||
E98BADD424BBFCB40040C7D4 /* picotest.c in Sources */,
|
||||
E98BADCF24BBFCA10040C7D4 /* picohttpparser.c in Sources */,
|
||||
E98BADD024BBFCA10040C7D4 /* test.c in Sources */,
|
||||
);
|
||||
runOnlyForDeploymentPostprocessing = 0;
|
||||
};
|
||||
/* End PBXSourcesBuildPhase section */
|
||||
|
||||
/* Begin XCBuildConfiguration section */
|
||||
E98BADC724BBFC4E0040C7D4 /* Debug */ = {
|
||||
isa = XCBuildConfiguration;
|
||||
buildSettings = {
|
||||
ALWAYS_SEARCH_USER_PATHS = NO;
|
||||
CLANG_ANALYZER_NONNULL = YES;
|
||||
CLANG_ANALYZER_NUMBER_OBJECT_CONVERSION = YES_AGGRESSIVE;
|
||||
CLANG_CXX_LANGUAGE_STANDARD = "gnu++14";
|
||||
CLANG_CXX_LIBRARY = "libc++";
|
||||
CLANG_ENABLE_MODULES = YES;
|
||||
CLANG_ENABLE_OBJC_ARC = YES;
|
||||
CLANG_ENABLE_OBJC_WEAK = YES;
|
||||
CLANG_WARN_BLOCK_CAPTURE_AUTORELEASING = YES;
|
||||
CLANG_WARN_BOOL_CONVERSION = YES;
|
||||
CLANG_WARN_COMMA = YES;
|
||||
CLANG_WARN_CONSTANT_CONVERSION = YES;
|
||||
CLANG_WARN_DEPRECATED_OBJC_IMPLEMENTATIONS = YES;
|
||||
CLANG_WARN_DIRECT_OBJC_ISA_USAGE = YES_ERROR;
|
||||
CLANG_WARN_DOCUMENTATION_COMMENTS = YES;
|
||||
CLANG_WARN_EMPTY_BODY = YES;
|
||||
CLANG_WARN_ENUM_CONVERSION = YES;
|
||||
CLANG_WARN_INFINITE_RECURSION = YES;
|
||||
CLANG_WARN_INT_CONVERSION = YES;
|
||||
CLANG_WARN_NON_LITERAL_NULL_CONVERSION = YES;
|
||||
CLANG_WARN_OBJC_IMPLICIT_RETAIN_SELF = YES;
|
||||
CLANG_WARN_OBJC_LITERAL_CONVERSION = YES;
|
||||
CLANG_WARN_OBJC_ROOT_CLASS = YES_ERROR;
|
||||
CLANG_WARN_RANGE_LOOP_ANALYSIS = YES;
|
||||
CLANG_WARN_STRICT_PROTOTYPES = YES;
|
||||
CLANG_WARN_SUSPICIOUS_MOVE = YES;
|
||||
CLANG_WARN_UNGUARDED_AVAILABILITY = YES_AGGRESSIVE;
|
||||
CLANG_WARN_UNREACHABLE_CODE = YES;
|
||||
CLANG_WARN__DUPLICATE_METHOD_MATCH = YES;
|
||||
COPY_PHASE_STRIP = NO;
|
||||
DEBUG_INFORMATION_FORMAT = dwarf;
|
||||
ENABLE_STRICT_OBJC_MSGSEND = YES;
|
||||
ENABLE_TESTABILITY = YES;
|
||||
GCC_C_LANGUAGE_STANDARD = gnu11;
|
||||
GCC_DYNAMIC_NO_PIC = NO;
|
||||
GCC_NO_COMMON_BLOCKS = YES;
|
||||
GCC_OPTIMIZATION_LEVEL = 0;
|
||||
GCC_PREPROCESSOR_DEFINITIONS = (
|
||||
"DEBUG=1",
|
||||
"$(inherited)",
|
||||
);
|
||||
GCC_WARN_64_TO_32_BIT_CONVERSION = YES;
|
||||
GCC_WARN_ABOUT_RETURN_TYPE = YES_ERROR;
|
||||
GCC_WARN_UNDECLARED_SELECTOR = YES;
|
||||
GCC_WARN_UNINITIALIZED_AUTOS = YES_AGGRESSIVE;
|
||||
GCC_WARN_UNUSED_FUNCTION = YES;
|
||||
GCC_WARN_UNUSED_VARIABLE = YES;
|
||||
MACOSX_DEPLOYMENT_TARGET = 10.15;
|
||||
MTL_ENABLE_DEBUG_INFO = INCLUDE_SOURCE;
|
||||
MTL_FAST_MATH = YES;
|
||||
ONLY_ACTIVE_ARCH = YES;
|
||||
SDKROOT = macosx;
|
||||
};
|
||||
name = Debug;
|
||||
};
|
||||
E98BADC824BBFC4E0040C7D4 /* Release */ = {
|
||||
isa = XCBuildConfiguration;
|
||||
buildSettings = {
|
||||
ALWAYS_SEARCH_USER_PATHS = NO;
|
||||
CLANG_ANALYZER_NONNULL = YES;
|
||||
CLANG_ANALYZER_NUMBER_OBJECT_CONVERSION = YES_AGGRESSIVE;
|
||||
CLANG_CXX_LANGUAGE_STANDARD = "gnu++14";
|
||||
CLANG_CXX_LIBRARY = "libc++";
|
||||
CLANG_ENABLE_MODULES = YES;
|
||||
CLANG_ENABLE_OBJC_ARC = YES;
|
||||
CLANG_ENABLE_OBJC_WEAK = YES;
|
||||
CLANG_WARN_BLOCK_CAPTURE_AUTORELEASING = YES;
|
||||
CLANG_WARN_BOOL_CONVERSION = YES;
|
||||
CLANG_WARN_COMMA = YES;
|
||||
CLANG_WARN_CONSTANT_CONVERSION = YES;
|
||||
CLANG_WARN_DEPRECATED_OBJC_IMPLEMENTATIONS = YES;
|
||||
CLANG_WARN_DIRECT_OBJC_ISA_USAGE = YES_ERROR;
|
||||
CLANG_WARN_DOCUMENTATION_COMMENTS = YES;
|
||||
CLANG_WARN_EMPTY_BODY = YES;
|
||||
CLANG_WARN_ENUM_CONVERSION = YES;
|
||||
CLANG_WARN_INFINITE_RECURSION = YES;
|
||||
CLANG_WARN_INT_CONVERSION = YES;
|
||||
CLANG_WARN_NON_LITERAL_NULL_CONVERSION = YES;
|
||||
CLANG_WARN_OBJC_IMPLICIT_RETAIN_SELF = YES;
|
||||
CLANG_WARN_OBJC_LITERAL_CONVERSION = YES;
|
||||
CLANG_WARN_OBJC_ROOT_CLASS = YES_ERROR;
|
||||
CLANG_WARN_RANGE_LOOP_ANALYSIS = YES;
|
||||
CLANG_WARN_STRICT_PROTOTYPES = YES;
|
||||
CLANG_WARN_SUSPICIOUS_MOVE = YES;
|
||||
CLANG_WARN_UNGUARDED_AVAILABILITY = YES_AGGRESSIVE;
|
||||
CLANG_WARN_UNREACHABLE_CODE = YES;
|
||||
CLANG_WARN__DUPLICATE_METHOD_MATCH = YES;
|
||||
COPY_PHASE_STRIP = NO;
|
||||
DEBUG_INFORMATION_FORMAT = "dwarf-with-dsym";
|
||||
ENABLE_NS_ASSERTIONS = NO;
|
||||
ENABLE_STRICT_OBJC_MSGSEND = YES;
|
||||
GCC_C_LANGUAGE_STANDARD = gnu11;
|
||||
GCC_NO_COMMON_BLOCKS = YES;
|
||||
GCC_WARN_64_TO_32_BIT_CONVERSION = YES;
|
||||
GCC_WARN_ABOUT_RETURN_TYPE = YES_ERROR;
|
||||
GCC_WARN_UNDECLARED_SELECTOR = YES;
|
||||
GCC_WARN_UNINITIALIZED_AUTOS = YES_AGGRESSIVE;
|
||||
GCC_WARN_UNUSED_FUNCTION = YES;
|
||||
GCC_WARN_UNUSED_VARIABLE = YES;
|
||||
MACOSX_DEPLOYMENT_TARGET = 10.15;
|
||||
MTL_ENABLE_DEBUG_INFO = NO;
|
||||
MTL_FAST_MATH = YES;
|
||||
SDKROOT = macosx;
|
||||
};
|
||||
name = Release;
|
||||
};
|
||||
E98BADCA24BBFC4E0040C7D4 /* Debug */ = {
|
||||
isa = XCBuildConfiguration;
|
||||
buildSettings = {
|
||||
CODE_SIGN_STYLE = Automatic;
|
||||
PRODUCT_NAME = "$(TARGET_NAME)";
|
||||
};
|
||||
name = Debug;
|
||||
};
|
||||
E98BADCB24BBFC4E0040C7D4 /* Release */ = {
|
||||
isa = XCBuildConfiguration;
|
||||
buildSettings = {
|
||||
CODE_SIGN_STYLE = Automatic;
|
||||
PRODUCT_NAME = "$(TARGET_NAME)";
|
||||
};
|
||||
name = Release;
|
||||
};
|
||||
/* End XCBuildConfiguration section */
|
||||
|
||||
/* Begin XCConfigurationList section */
|
||||
E98BADBD24BBFC4E0040C7D4 /* Build configuration list for PBXProject "picohttpparser" */ = {
|
||||
isa = XCConfigurationList;
|
||||
buildConfigurations = (
|
||||
E98BADC724BBFC4E0040C7D4 /* Debug */,
|
||||
E98BADC824BBFC4E0040C7D4 /* Release */,
|
||||
);
|
||||
defaultConfigurationIsVisible = 0;
|
||||
defaultConfigurationName = Release;
|
||||
};
|
||||
E98BADC924BBFC4E0040C7D4 /* Build configuration list for PBXNativeTarget "test" */ = {
|
||||
isa = XCConfigurationList;
|
||||
buildConfigurations = (
|
||||
E98BADCA24BBFC4E0040C7D4 /* Debug */,
|
||||
E98BADCB24BBFC4E0040C7D4 /* Release */,
|
||||
);
|
||||
defaultConfigurationIsVisible = 0;
|
||||
defaultConfigurationName = Release;
|
||||
};
|
||||
/* End XCConfigurationList section */
|
||||
};
|
||||
rootObject = E98BADBA24BBFC4E0040C7D4 /* Project object */;
|
||||
}
|
||||
7
deps/picohttpparser/picohttpparser.xcodeproj/project.xcworkspace/contents.xcworkspacedata
generated
vendored
Normal file
7
deps/picohttpparser/picohttpparser.xcodeproj/project.xcworkspace/contents.xcworkspacedata
generated
vendored
Normal file
@@ -0,0 +1,7 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<Workspace
|
||||
version = "1.0">
|
||||
<FileRef
|
||||
location = "self:">
|
||||
</FileRef>
|
||||
</Workspace>
|
||||
@@ -0,0 +1,8 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
|
||||
<plist version="1.0">
|
||||
<dict>
|
||||
<key>IDEDidComputeMac32BitWarning</key>
|
||||
<true/>
|
||||
</dict>
|
||||
</plist>
|
||||
95
deps/picohttpparser/picohttpparser.xcodeproj/xcshareddata/xcschemes/test.xcscheme
vendored
Normal file
95
deps/picohttpparser/picohttpparser.xcodeproj/xcshareddata/xcschemes/test.xcscheme
vendored
Normal file
@@ -0,0 +1,95 @@
|
||||
<?xml version="1.0" encoding="UTF-8"?>
|
||||
<Scheme
|
||||
LastUpgradeVersion = "1150"
|
||||
version = "1.3">
|
||||
<BuildAction
|
||||
parallelizeBuildables = "YES"
|
||||
buildImplicitDependencies = "YES">
|
||||
<BuildActionEntries>
|
||||
<BuildActionEntry
|
||||
buildForTesting = "YES"
|
||||
buildForRunning = "YES"
|
||||
buildForProfiling = "YES"
|
||||
buildForArchiving = "YES"
|
||||
buildForAnalyzing = "YES">
|
||||
<BuildableReference
|
||||
BuildableIdentifier = "primary"
|
||||
BlueprintIdentifier = "E98BADC124BBFC4E0040C7D4"
|
||||
BuildableName = "test"
|
||||
BlueprintName = "test"
|
||||
ReferencedContainer = "container:picohttpparser.xcodeproj">
|
||||
</BuildableReference>
|
||||
</BuildActionEntry>
|
||||
</BuildActionEntries>
|
||||
</BuildAction>
|
||||
<TestAction
|
||||
buildConfiguration = "Debug"
|
||||
selectedDebuggerIdentifier = "Xcode.DebuggerFoundation.Debugger.LLDB"
|
||||
selectedLauncherIdentifier = "Xcode.DebuggerFoundation.Launcher.LLDB"
|
||||
shouldUseLaunchSchemeArgsEnv = "YES">
|
||||
<Testables>
|
||||
</Testables>
|
||||
</TestAction>
|
||||
<LaunchAction
|
||||
buildConfiguration = "Debug"
|
||||
selectedDebuggerIdentifier = "Xcode.DebuggerFoundation.Debugger.LLDB"
|
||||
selectedLauncherIdentifier = "Xcode.DebuggerFoundation.Launcher.LLDB"
|
||||
launchStyle = "0"
|
||||
useCustomWorkingDirectory = "NO"
|
||||
ignoresPersistentStateOnLaunch = "NO"
|
||||
debugDocumentVersioning = "YES"
|
||||
debugServiceExtension = "internal"
|
||||
allowLocationSimulation = "YES">
|
||||
<BuildableProductRunnable
|
||||
runnableDebuggingMode = "0">
|
||||
<BuildableReference
|
||||
BuildableIdentifier = "primary"
|
||||
BlueprintIdentifier = "E98BADC124BBFC4E0040C7D4"
|
||||
BuildableName = "test"
|
||||
BlueprintName = "test"
|
||||
ReferencedContainer = "container:picohttpparser.xcodeproj">
|
||||
</BuildableReference>
|
||||
</BuildableProductRunnable>
|
||||
<AdditionalOptions>
|
||||
<AdditionalOption
|
||||
key = "DYLD_INSERT_LIBRARIES"
|
||||
value = "/usr/lib/libgmalloc.dylib"
|
||||
isEnabled = "YES">
|
||||
</AdditionalOption>
|
||||
<AdditionalOption
|
||||
key = "MallocGuardEdges"
|
||||
value = ""
|
||||
isEnabled = "YES">
|
||||
</AdditionalOption>
|
||||
<AdditionalOption
|
||||
key = "MallocScribble"
|
||||
value = ""
|
||||
isEnabled = "YES">
|
||||
</AdditionalOption>
|
||||
</AdditionalOptions>
|
||||
</LaunchAction>
|
||||
<ProfileAction
|
||||
buildConfiguration = "Release"
|
||||
shouldUseLaunchSchemeArgsEnv = "YES"
|
||||
savedToolIdentifier = ""
|
||||
useCustomWorkingDirectory = "NO"
|
||||
debugDocumentVersioning = "YES">
|
||||
<BuildableProductRunnable
|
||||
runnableDebuggingMode = "0">
|
||||
<BuildableReference
|
||||
BuildableIdentifier = "primary"
|
||||
BlueprintIdentifier = "E98BADC124BBFC4E0040C7D4"
|
||||
BuildableName = "test"
|
||||
BlueprintName = "test"
|
||||
ReferencedContainer = "container:picohttpparser.xcodeproj">
|
||||
</BuildableReference>
|
||||
</BuildableProductRunnable>
|
||||
</ProfileAction>
|
||||
<AnalyzeAction
|
||||
buildConfiguration = "Debug">
|
||||
</AnalyzeAction>
|
||||
<ArchiveAction
|
||||
buildConfiguration = "Release"
|
||||
revealArchiveInOrganizer = "YES">
|
||||
</ArchiveAction>
|
||||
</Scheme>
|
||||
479
deps/picohttpparser/test.c
vendored
Normal file
479
deps/picohttpparser/test.c
vendored
Normal file
@@ -0,0 +1,479 @@
|
||||
/* use `make test` to run the test */
|
||||
/*
|
||||
* Copyright (c) 2009-2014 Kazuho Oku, Tokuhiro Matsuno, Daisuke Murase,
|
||||
* Shigeo Mitsunari
|
||||
*
|
||||
* The software is licensed under either the MIT License (below) or the Perl
|
||||
* license.
|
||||
*
|
||||
* Permission is hereby granted, free of charge, to any person obtaining a copy
|
||||
* of this software and associated documentation files (the "Software"), to
|
||||
* deal in the Software without restriction, including without limitation the
|
||||
* rights to use, copy, modify, merge, publish, distribute, sublicense, and/or
|
||||
* sell copies of the Software, and to permit persons to whom the Software is
|
||||
* furnished to do so, subject to the following conditions:
|
||||
*
|
||||
* The above copyright notice and this permission notice shall be included in
|
||||
* all copies or substantial portions of the Software.
|
||||
*
|
||||
* THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
|
||||
* IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
|
||||
* FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
|
||||
* AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
|
||||
* LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING
|
||||
* FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS
|
||||
* IN THE SOFTWARE.
|
||||
*/
|
||||
#include <assert.h>
|
||||
#include <stdio.h>
|
||||
#include <stdlib.h>
|
||||
#include <string.h>
|
||||
#include <sys/mman.h>
|
||||
#include <sys/types.h>
|
||||
#include <unistd.h>
|
||||
#include "picotest/picotest.h"
|
||||
#include "picohttpparser.h"
|
||||
|
||||
static int bufis(const char *s, size_t l, const char *t)
|
||||
{
|
||||
return strlen(t) == l && memcmp(s, t, l) == 0;
|
||||
}
|
||||
|
||||
static char *inputbuf; /* point to the end of the buffer */
|
||||
|
||||
static void test_request(void)
|
||||
{
|
||||
const char *method;
|
||||
size_t method_len;
|
||||
const char *path;
|
||||
size_t path_len;
|
||||
int minor_version;
|
||||
struct phr_header headers[4];
|
||||
size_t num_headers;
|
||||
|
||||
#define PARSE(s, last_len, exp, comment) \
|
||||
do { \
|
||||
size_t slen = sizeof(s) - 1; \
|
||||
note(comment); \
|
||||
num_headers = sizeof(headers) / sizeof(headers[0]); \
|
||||
memcpy(inputbuf - slen, s, slen); \
|
||||
ok(phr_parse_request(inputbuf - slen, slen, &method, &method_len, &path, &path_len, &minor_version, headers, &num_headers, \
|
||||
last_len) == (exp == 0 ? (int)slen : exp)); \
|
||||
} while (0)
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\n\r\n", 0, 0, "simple");
|
||||
ok(num_headers == 0);
|
||||
ok(bufis(method, method_len, "GET"));
|
||||
ok(bufis(path, path_len, "/"));
|
||||
ok(minor_version == 0);
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\n\r", 0, -2, "partial");
|
||||
|
||||
PARSE("GET /hoge HTTP/1.1\r\nHost: example.com\r\nCookie: \r\n\r\n", 0, 0, "parse headers");
|
||||
ok(num_headers == 2);
|
||||
ok(bufis(method, method_len, "GET"));
|
||||
ok(bufis(path, path_len, "/hoge"));
|
||||
ok(minor_version == 1);
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "Host"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "example.com"));
|
||||
ok(bufis(headers[1].name, headers[1].name_len, "Cookie"));
|
||||
ok(bufis(headers[1].value, headers[1].value_len, ""));
|
||||
|
||||
PARSE("GET /hoge HTTP/1.1\r\nHost: example.com\r\nUser-Agent: \343\201\262\343/1.0\r\n\r\n", 0, 0, "multibyte included");
|
||||
ok(num_headers == 2);
|
||||
ok(bufis(method, method_len, "GET"));
|
||||
ok(bufis(path, path_len, "/hoge"));
|
||||
ok(minor_version == 1);
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "Host"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "example.com"));
|
||||
ok(bufis(headers[1].name, headers[1].name_len, "User-Agent"));
|
||||
ok(bufis(headers[1].value, headers[1].value_len, "\343\201\262\343/1.0"));
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\nfoo: \r\nfoo: b\r\n \tc\r\n\r\n", 0, 0, "parse multiline");
|
||||
ok(num_headers == 3);
|
||||
ok(bufis(method, method_len, "GET"));
|
||||
ok(bufis(path, path_len, "/"));
|
||||
ok(minor_version == 0);
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "foo"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, ""));
|
||||
ok(bufis(headers[1].name, headers[1].name_len, "foo"));
|
||||
ok(bufis(headers[1].value, headers[1].value_len, "b"));
|
||||
ok(headers[2].name == NULL);
|
||||
ok(bufis(headers[2].value, headers[2].value_len, " \tc"));
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\nfoo : ab\r\n\r\n", 0, -1, "parse header name with trailing space");
|
||||
|
||||
PARSE("GET", 0, -2, "incomplete 1");
|
||||
ok(method == NULL);
|
||||
PARSE("GET ", 0, -2, "incomplete 2");
|
||||
ok(bufis(method, method_len, "GET"));
|
||||
PARSE("GET /", 0, -2, "incomplete 3");
|
||||
ok(path == NULL);
|
||||
PARSE("GET / ", 0, -2, "incomplete 4");
|
||||
ok(bufis(path, path_len, "/"));
|
||||
PARSE("GET / H", 0, -2, "incomplete 5");
|
||||
PARSE("GET / HTTP/1.", 0, -2, "incomplete 6");
|
||||
PARSE("GET / HTTP/1.0", 0, -2, "incomplete 7");
|
||||
ok(minor_version == -1);
|
||||
PARSE("GET / HTTP/1.0\r", 0, -2, "incomplete 8");
|
||||
ok(minor_version == 0);
|
||||
|
||||
PARSE("GET /hoge HTTP/1.0\r\n\r", strlen("GET /hoge HTTP/1.0\r\n\r") - 1, -2, "slowloris (incomplete)");
|
||||
PARSE("GET /hoge HTTP/1.0\r\n\r\n", strlen("GET /hoge HTTP/1.0\r\n\r\n") - 1, 0, "slowloris (complete)");
|
||||
|
||||
PARSE(" / HTTP/1.0\r\n\r\n", 0, -1, "empty method");
|
||||
PARSE("GET HTTP/1.0\r\n\r\n", 0, -1, "empty request-target");
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\n:a\r\n\r\n", 0, -1, "empty header name");
|
||||
PARSE("GET / HTTP/1.0\r\n :a\r\n\r\n", 0, -1, "header name (space only)");
|
||||
|
||||
PARSE("G\0T / HTTP/1.0\r\n\r\n", 0, -1, "NUL in method");
|
||||
PARSE("G\tT / HTTP/1.0\r\n\r\n", 0, -1, "tab in method");
|
||||
PARSE(":GET / HTTP/1.0\r\n\r\n", 0, -1, "invalid method");
|
||||
PARSE("GET /\x7fhello HTTP/1.0\r\n\r\n", 0, -1, "DEL in uri-path");
|
||||
PARSE("GET / HTTP/1.0\r\na\0b: c\r\n\r\n", 0, -1, "NUL in header name");
|
||||
PARSE("GET / HTTP/1.0\r\nab: c\0d\r\n\r\n", 0, -1, "NUL in header value");
|
||||
PARSE("GET / HTTP/1.0\r\na\033b: c\r\n\r\n", 0, -1, "CTL in header name");
|
||||
PARSE("GET / HTTP/1.0\r\nab: c\033\r\n\r\n", 0, -1, "CTL in header value");
|
||||
PARSE("GET / HTTP/1.0\r\n/: 1\r\n\r\n", 0, -1, "invalid char in header value");
|
||||
PARSE("GET /\xa0 HTTP/1.0\r\nh: c\xa2y\r\n\r\n", 0, 0, "accept MSB chars");
|
||||
ok(num_headers == 1);
|
||||
ok(bufis(method, method_len, "GET"));
|
||||
ok(bufis(path, path_len, "/\xa0"));
|
||||
ok(minor_version == 0);
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "h"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "c\xa2y"));
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\n\x7c\x7e: 1\r\n\r\n", 0, 0, "accept |~ (though forbidden by SSE)");
|
||||
ok(num_headers == 1);
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "\x7c\x7e"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "1"));
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\n\x7b: 1\r\n\r\n", 0, -1, "disallow {");
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\nfoo: a \t \r\n\r\n", 0, 0, "exclude leading and trailing spaces in header value");
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "a"));
|
||||
|
||||
PARSE("GET / HTTP/1.0\r\n\r\n", 0, 0, "accept multiple spaces between tokens");
|
||||
|
||||
#undef PARSE
|
||||
}
|
||||
|
||||
static void test_response(void)
|
||||
{
|
||||
int minor_version;
|
||||
int status;
|
||||
const char *msg;
|
||||
size_t msg_len;
|
||||
struct phr_header headers[4];
|
||||
size_t num_headers;
|
||||
|
||||
#define PARSE(s, last_len, exp, comment) \
|
||||
do { \
|
||||
size_t slen = sizeof(s) - 1; \
|
||||
note(comment); \
|
||||
num_headers = sizeof(headers) / sizeof(headers[0]); \
|
||||
memcpy(inputbuf - slen, s, slen); \
|
||||
ok(phr_parse_response(inputbuf - slen, slen, &minor_version, &status, &msg, &msg_len, headers, &num_headers, last_len) == \
|
||||
(exp == 0 ? (int)slen : exp)); \
|
||||
} while (0)
|
||||
|
||||
PARSE("HTTP/1.0 200 OK\r\n\r\n", 0, 0, "simple");
|
||||
ok(num_headers == 0);
|
||||
ok(status == 200);
|
||||
ok(minor_version == 0);
|
||||
ok(bufis(msg, msg_len, "OK"));
|
||||
|
||||
PARSE("HTTP/1.0 200 OK\r\n\r", 0, -2, "partial");
|
||||
|
||||
PARSE("HTTP/1.1 200 OK\r\nHost: example.com\r\nCookie: \r\n\r\n", 0, 0, "parse headers");
|
||||
ok(num_headers == 2);
|
||||
ok(minor_version == 1);
|
||||
ok(status == 200);
|
||||
ok(bufis(msg, msg_len, "OK"));
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "Host"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "example.com"));
|
||||
ok(bufis(headers[1].name, headers[1].name_len, "Cookie"));
|
||||
ok(bufis(headers[1].value, headers[1].value_len, ""));
|
||||
|
||||
PARSE("HTTP/1.0 200 OK\r\nfoo: \r\nfoo: b\r\n \tc\r\n\r\n", 0, 0, "parse multiline");
|
||||
ok(num_headers == 3);
|
||||
ok(minor_version == 0);
|
||||
ok(status == 200);
|
||||
ok(bufis(msg, msg_len, "OK"));
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "foo"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, ""));
|
||||
ok(bufis(headers[1].name, headers[1].name_len, "foo"));
|
||||
ok(bufis(headers[1].value, headers[1].value_len, "b"));
|
||||
ok(headers[2].name == NULL);
|
||||
ok(bufis(headers[2].value, headers[2].value_len, " \tc"));
|
||||
|
||||
PARSE("HTTP/1.0 500 Internal Server Error\r\n\r\n", 0, 0, "internal server error");
|
||||
ok(num_headers == 0);
|
||||
ok(minor_version == 0);
|
||||
ok(status == 500);
|
||||
ok(bufis(msg, msg_len, "Internal Server Error"));
|
||||
ok(msg_len == sizeof("Internal Server Error") - 1);
|
||||
|
||||
PARSE("H", 0, -2, "incomplete 1");
|
||||
PARSE("HTTP/1.", 0, -2, "incomplete 2");
|
||||
PARSE("HTTP/1.1", 0, -2, "incomplete 3");
|
||||
ok(minor_version == -1);
|
||||
PARSE("HTTP/1.1 ", 0, -2, "incomplete 4");
|
||||
ok(minor_version == 1);
|
||||
PARSE("HTTP/1.1 2", 0, -2, "incomplete 5");
|
||||
PARSE("HTTP/1.1 200", 0, -2, "incomplete 6");
|
||||
ok(status == 0);
|
||||
PARSE("HTTP/1.1 200 ", 0, -2, "incomplete 7");
|
||||
ok(status == 200);
|
||||
PARSE("HTTP/1.1 200 O", 0, -2, "incomplete 8");
|
||||
PARSE("HTTP/1.1 200 OK\r", 0, -2, "incomplete 9");
|
||||
ok(msg == NULL);
|
||||
PARSE("HTTP/1.1 200 OK\r\n", 0, -2, "incomplete 10");
|
||||
ok(bufis(msg, msg_len, "OK"));
|
||||
PARSE("HTTP/1.1 200 OK\n", 0, -2, "incomplete 11");
|
||||
ok(bufis(msg, msg_len, "OK"));
|
||||
|
||||
PARSE("HTTP/1.1 200 OK\r\nA: 1\r", 0, -2, "incomplete 11");
|
||||
ok(num_headers == 0);
|
||||
PARSE("HTTP/1.1 200 OK\r\nA: 1\r\n", 0, -2, "incomplete 12");
|
||||
ok(num_headers == 1);
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "A"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "1"));
|
||||
|
||||
PARSE("HTTP/1.0 200 OK\r\n\r", strlen("HTTP/1.0 200 OK\r\n\r") - 1, -2, "slowloris (incomplete)");
|
||||
PARSE("HTTP/1.0 200 OK\r\n\r\n", strlen("HTTP/1.0 200 OK\r\n\r\n") - 1, 0, "slowloris (complete)");
|
||||
|
||||
PARSE("HTTP/1. 200 OK\r\n\r\n", 0, -1, "invalid http version");
|
||||
PARSE("HTTP/1.2z 200 OK\r\n\r\n", 0, -1, "invalid http version 2");
|
||||
PARSE("HTTP/1.1 OK\r\n\r\n", 0, -1, "no status code");
|
||||
|
||||
PARSE("HTTP/1.1 200\r\n\r\n", 0, 0, "accept missing trailing whitespace in status-line");
|
||||
ok(bufis(msg, msg_len, ""));
|
||||
PARSE("HTTP/1.1 200X\r\n\r\n", 0, -1, "garbage after status 1");
|
||||
PARSE("HTTP/1.1 200X \r\n\r\n", 0, -1, "garbage after status 2");
|
||||
PARSE("HTTP/1.1 200X OK\r\n\r\n", 0, -1, "garbage after status 3");
|
||||
|
||||
PARSE("HTTP/1.1 200 OK\r\nbar: \t b\t \t\r\n\r\n", 0, 0, "exclude leading and trailing spaces in header value");
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "b"));
|
||||
|
||||
PARSE("HTTP/1.1 200 OK\r\n\r\n", 0, 0, "accept multiple spaces between tokens");
|
||||
|
||||
#undef PARSE
|
||||
}
|
||||
|
||||
static void test_headers(void)
|
||||
{
|
||||
/* only test the interface; the core parser is tested by the tests above */
|
||||
|
||||
struct phr_header headers[4];
|
||||
size_t num_headers;
|
||||
|
||||
#define PARSE(s, last_len, exp, comment) \
|
||||
do { \
|
||||
note(comment); \
|
||||
num_headers = sizeof(headers) / sizeof(headers[0]); \
|
||||
ok(phr_parse_headers(s, strlen(s), headers, &num_headers, last_len) == (exp == 0 ? (int)strlen(s) : exp)); \
|
||||
} while (0)
|
||||
|
||||
PARSE("Host: example.com\r\nCookie: \r\n\r\n", 0, 0, "simple");
|
||||
ok(num_headers == 2);
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "Host"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "example.com"));
|
||||
ok(bufis(headers[1].name, headers[1].name_len, "Cookie"));
|
||||
ok(bufis(headers[1].value, headers[1].value_len, ""));
|
||||
|
||||
PARSE("Host: example.com\r\nCookie: \r\n\r\n", 1, 0, "slowloris");
|
||||
ok(num_headers == 2);
|
||||
ok(bufis(headers[0].name, headers[0].name_len, "Host"));
|
||||
ok(bufis(headers[0].value, headers[0].value_len, "example.com"));
|
||||
ok(bufis(headers[1].name, headers[1].name_len, "Cookie"));
|
||||
ok(bufis(headers[1].value, headers[1].value_len, ""));
|
||||
|
||||
PARSE("Host: example.com\r\nCookie: \r\n\r", 0, -2, "partial");
|
||||
|
||||
PARSE("Host: e\7fample.com\r\nCookie: \r\n\r", 0, -1, "error");
|
||||
|
||||
#undef PARSE
|
||||
}
|
||||
|
||||
static void test_chunked_at_once(int line, int consume_trailer, const char *encoded, const char *decoded, ssize_t expected)
|
||||
{
|
||||
struct phr_chunked_decoder dec = {0};
|
||||
char *buf;
|
||||
size_t bufsz;
|
||||
ssize_t ret;
|
||||
|
||||
dec.consume_trailer = consume_trailer;
|
||||
|
||||
note("testing at-once, source at line %d", line);
|
||||
|
||||
buf = strdup(encoded);
|
||||
bufsz = strlen(buf);
|
||||
|
||||
ret = phr_decode_chunked(&dec, buf, &bufsz);
|
||||
|
||||
ok(ret == expected);
|
||||
ok(bufsz == strlen(decoded));
|
||||
ok(bufis(buf, bufsz, decoded));
|
||||
if (expected >= 0) {
|
||||
if (ret == expected)
|
||||
ok(bufis(buf + bufsz, ret, encoded + strlen(encoded) - ret));
|
||||
else
|
||||
ok(0);
|
||||
}
|
||||
|
||||
free(buf);
|
||||
}
|
||||
|
||||
static void test_chunked_per_byte(int line, int consume_trailer, const char *encoded, const char *decoded, ssize_t expected)
|
||||
{
|
||||
struct phr_chunked_decoder dec = {0};
|
||||
char *buf = malloc(strlen(encoded) + 1);
|
||||
size_t bytes_to_consume = strlen(encoded) - (expected >= 0 ? expected : 0), bytes_ready = 0, bufsz, i;
|
||||
ssize_t ret;
|
||||
|
||||
dec.consume_trailer = consume_trailer;
|
||||
|
||||
note("testing per-byte, source at line %d", line);
|
||||
|
||||
for (i = 0; i < bytes_to_consume - 1; ++i) {
|
||||
buf[bytes_ready] = encoded[i];
|
||||
bufsz = 1;
|
||||
ret = phr_decode_chunked(&dec, buf + bytes_ready, &bufsz);
|
||||
if (ret != -2) {
|
||||
ok(0);
|
||||
goto cleanup;
|
||||
}
|
||||
bytes_ready += bufsz;
|
||||
}
|
||||
strcpy(buf + bytes_ready, encoded + bytes_to_consume - 1);
|
||||
bufsz = strlen(buf + bytes_ready);
|
||||
ret = phr_decode_chunked(&dec, buf + bytes_ready, &bufsz);
|
||||
ok(ret == expected);
|
||||
bytes_ready += bufsz;
|
||||
ok(bytes_ready == strlen(decoded));
|
||||
ok(bufis(buf, bytes_ready, decoded));
|
||||
if (expected >= 0) {
|
||||
if (ret == expected)
|
||||
ok(bufis(buf + bytes_ready, expected, encoded + bytes_to_consume));
|
||||
else
|
||||
ok(0);
|
||||
}
|
||||
|
||||
cleanup:
|
||||
free(buf);
|
||||
}
|
||||
|
||||
static void test_chunked_failure(int line, const char *encoded, ssize_t expected)
|
||||
{
|
||||
struct phr_chunked_decoder dec = {0};
|
||||
char *buf = strdup(encoded);
|
||||
size_t bufsz, i;
|
||||
ssize_t ret;
|
||||
|
||||
note("testing failure at-once, source at line %d", line);
|
||||
bufsz = strlen(buf);
|
||||
ret = phr_decode_chunked(&dec, buf, &bufsz);
|
||||
ok(ret == expected);
|
||||
|
||||
note("testing failure per-byte, source at line %d", line);
|
||||
memset(&dec, 0, sizeof(dec));
|
||||
for (i = 0; encoded[i] != '\0'; ++i) {
|
||||
buf[0] = encoded[i];
|
||||
bufsz = 1;
|
||||
ret = phr_decode_chunked(&dec, buf, &bufsz);
|
||||
if (ret == -1) {
|
||||
ok(ret == expected);
|
||||
goto cleanup;
|
||||
} else if (ret == -2) {
|
||||
/* continue */
|
||||
} else {
|
||||
ok(0);
|
||||
goto cleanup;
|
||||
}
|
||||
}
|
||||
ok(ret == expected);
|
||||
|
||||
cleanup:
|
||||
free(buf);
|
||||
}
|
||||
|
||||
static void (*chunked_test_runners[])(int, int, const char *, const char *, ssize_t) = {test_chunked_at_once, test_chunked_per_byte,
|
||||
NULL};
|
||||
|
||||
static void test_chunked(void)
|
||||
{
|
||||
size_t i;
|
||||
|
||||
for (i = 0; chunked_test_runners[i] != NULL; ++i) {
|
||||
chunked_test_runners[i](__LINE__, 0, "b\r\nhello world\r\n0\r\n", "hello world", 0);
|
||||
chunked_test_runners[i](__LINE__, 0, "6\r\nhello \r\n5\r\nworld\r\n0\r\n", "hello world", 0);
|
||||
chunked_test_runners[i](__LINE__, 0, "6;comment=hi\r\nhello \r\n5\r\nworld\r\n0\r\n", "hello world", 0);
|
||||
chunked_test_runners[i](__LINE__, 0, "6\r\nhello \r\n5\r\nworld\r\n0\r\na: b\r\nc: d\r\n\r\n", "hello world",
|
||||
sizeof("a: b\r\nc: d\r\n\r\n") - 1);
|
||||
chunked_test_runners[i](__LINE__, 0, "b\r\nhello world\r\n0\r\n", "hello world", 0);
|
||||
}
|
||||
|
||||
note("failures");
|
||||
test_chunked_failure(__LINE__, "z\r\nabcdefg", -1);
|
||||
if (sizeof(size_t) == 8) {
|
||||
test_chunked_failure(__LINE__, "6\r\nhello \r\nffffffffffffffff\r\nabcdefg", -2);
|
||||
test_chunked_failure(__LINE__, "6\r\nhello \r\nfffffffffffffffff\r\nabcdefg", -1);
|
||||
}
|
||||
}
|
||||
|
||||
static void test_chunked_consume_trailer(void)
|
||||
{
|
||||
size_t i;
|
||||
|
||||
for (i = 0; chunked_test_runners[i] != NULL; ++i) {
|
||||
chunked_test_runners[i](__LINE__, 1, "b\r\nhello world\r\n0\r\n", "hello world", -2);
|
||||
chunked_test_runners[i](__LINE__, 1, "6\r\nhello \r\n5\r\nworld\r\n0\r\n", "hello world", -2);
|
||||
chunked_test_runners[i](__LINE__, 1, "6;comment=hi\r\nhello \r\n5\r\nworld\r\n0\r\n", "hello world", -2);
|
||||
chunked_test_runners[i](__LINE__, 1, "b\r\nhello world\r\n0\r\n\r\n", "hello world", 0);
|
||||
chunked_test_runners[i](__LINE__, 1, "b\nhello world\n0\n\n", "hello world", 0);
|
||||
chunked_test_runners[i](__LINE__, 1, "6\r\nhello \r\n5\r\nworld\r\n0\r\na: b\r\nc: d\r\n\r\n", "hello world", 0);
|
||||
}
|
||||
}
|
||||
|
||||
static void test_chunked_leftdata(void)
|
||||
{
|
||||
#define NEXT_REQ "GET / HTTP/1.1\r\n\r\n"
|
||||
|
||||
struct phr_chunked_decoder dec = {0};
|
||||
dec.consume_trailer = 1;
|
||||
char buf[] = "5\r\nabcde\r\n0\r\n\r\n" NEXT_REQ;
|
||||
size_t bufsz = sizeof(buf) - 1;
|
||||
|
||||
ssize_t ret = phr_decode_chunked(&dec, buf, &bufsz);
|
||||
ok(ret >= 0);
|
||||
ok(bufsz == 5);
|
||||
ok(memcmp(buf, "abcde", 5) == 0);
|
||||
ok(ret == sizeof(NEXT_REQ) - 1);
|
||||
ok(memcmp(buf + bufsz, NEXT_REQ, sizeof(NEXT_REQ) - 1) == 0);
|
||||
|
||||
#undef NEXT_REQ
|
||||
}
|
||||
|
||||
int main(void)
|
||||
{
|
||||
long pagesize = sysconf(_SC_PAGESIZE);
|
||||
assert(pagesize >= 1);
|
||||
|
||||
inputbuf = mmap(NULL, pagesize * 3, PROT_NONE, MAP_ANON | MAP_PRIVATE, -1, 0);
|
||||
assert(inputbuf != MAP_FAILED);
|
||||
inputbuf += pagesize * 2;
|
||||
ok(mprotect(inputbuf - pagesize, pagesize, PROT_READ | PROT_WRITE) == 0);
|
||||
|
||||
subtest("request", test_request);
|
||||
subtest("response", test_response);
|
||||
subtest("headers", test_headers);
|
||||
subtest("chunked", test_chunked);
|
||||
subtest("chunked-consume-trailer", test_chunked_consume_trailer);
|
||||
subtest("chunked-leftdata", test_chunked_leftdata);
|
||||
|
||||
munmap(inputbuf - pagesize * 2, pagesize * 3);
|
||||
|
||||
return done_testing();
|
||||
}
|
||||
@@ -5,6 +5,7 @@
|
||||
#include "trace.h"
|
||||
|
||||
#include <base64c.h>
|
||||
#include <picohttpparser.h>
|
||||
#include <quickjs-libc.h>
|
||||
#include <uv.h>
|
||||
|
||||
@@ -228,6 +229,68 @@ static JSValue _util_setTimeout(JSContext* context, JSValueConst this_val, int a
|
||||
return JS_NULL;
|
||||
}
|
||||
|
||||
static JSValue _util_parseHttp(JSContext* context, JSValueConst this_val, int argc, JSValueConst* argv)
|
||||
{
|
||||
JSValue result = JS_UNDEFINED;
|
||||
const char* method = NULL;
|
||||
size_t method_length = 0;
|
||||
const char* path = NULL;
|
||||
size_t path_length = 0;
|
||||
int minor_version = 0;
|
||||
struct phr_header headers[100];
|
||||
size_t header_count = sizeof(headers) / sizeof(*headers);
|
||||
int previous_length = 0;
|
||||
JS_ToInt32(context, &previous_length, argv[1]);
|
||||
|
||||
JSValue buffer = JS_UNDEFINED;
|
||||
size_t length;
|
||||
uint8_t* array = tf_util_try_get_array_buffer(context, &length, argv[0]);
|
||||
if (!array)
|
||||
{
|
||||
size_t offset;
|
||||
size_t element_size;
|
||||
buffer = tf_util_try_get_typed_array_buffer(context, argv[0], &offset, &length, &element_size);
|
||||
if (!JS_IsException(buffer))
|
||||
{
|
||||
array = tf_util_try_get_array_buffer(context, &length, buffer);
|
||||
}
|
||||
}
|
||||
|
||||
if (array)
|
||||
{
|
||||
int parse_result = phr_parse_request((const char*)array, length, &method, &method_length, &path, &path_length, &minor_version, headers, &header_count, 0);
|
||||
if (parse_result > 0)
|
||||
{
|
||||
result = JS_NewObject(context);
|
||||
JS_SetPropertyStr(context, result, "bytes_parsed", JS_NewInt32(context, parse_result));
|
||||
JS_SetPropertyStr(context, result, "minor_version", JS_NewInt32(context, minor_version));
|
||||
JS_SetPropertyStr(context, result, "method", JS_NewStringLen(context, method, method_length));
|
||||
JS_SetPropertyStr(context, result, "path", JS_NewStringLen(context, path, path_length));
|
||||
JSValue header_object = JS_NewObject(context);
|
||||
for (int i = 0; i < (int)header_count; i++)
|
||||
{
|
||||
char name[256];
|
||||
snprintf(name, sizeof(name), "%.*s", (int)headers[i].name_len, headers[i].name);
|
||||
JS_SetPropertyStr(context, header_object, name, JS_NewStringLen(context, headers[i].value, headers[i].value_len));
|
||||
}
|
||||
JS_SetPropertyStr(context, result, "headers", header_object);
|
||||
}
|
||||
else
|
||||
{
|
||||
result = JS_NewInt32(context, parse_result);
|
||||
}
|
||||
}
|
||||
else
|
||||
{
|
||||
result = JS_ThrowTypeError(context, "Could not convert argument to array.");
|
||||
}
|
||||
|
||||
JS_FreeValue(context, buffer);
|
||||
|
||||
return result;
|
||||
|
||||
}
|
||||
|
||||
void tf_util_register(JSContext* context)
|
||||
{
|
||||
JSValue global = JS_GetGlobalObject(context);
|
||||
@@ -237,6 +300,7 @@ void tf_util_register(JSContext* context)
|
||||
JS_SetPropertyStr(context, global, "base64Encode", JS_NewCFunction(context, _util_base64_encode, "base64Encode", 1));
|
||||
JS_SetPropertyStr(context, global, "print", JS_NewCFunction(context, _util_print, "print", 1));
|
||||
JS_SetPropertyStr(context, global, "setTimeout", JS_NewCFunction(context, _util_setTimeout, "setTimeout", 2));
|
||||
JS_SetPropertyStr(context, global, "parseHttp", JS_NewCFunction(context, _util_parseHttp, "parseHttp", 2));
|
||||
JS_FreeValue(context, global);
|
||||
}
|
||||
|
||||
|
||||
Reference in New Issue
Block a user